'linalg' Dialect
Rationale
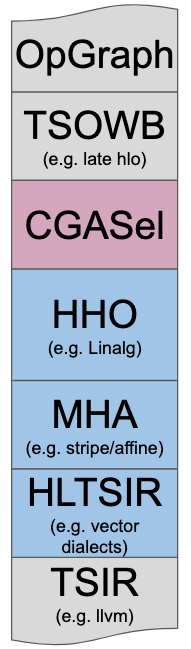
Linalg is designed to solve the High-level Hierarchical Optimization (HHO box) in MLIR and to interoperate nicely within a Mixture Of Expert Compilers environment (i.e. the CGSel box).
The Rationale Document goes into significantly more design and architectural decision details.
Set of Key Transformations
The following key transformations have been central to driving the design of
Linalg. They are all implemented in terms of the properties of the
linalg.generic OpInterface and avoid the pitfall of relying on hardcoded
one-off op knowledge.
The textual form description of these transformations is left for future work. Still, it is useful to list the key transformations that are performed on the Linalg IR and that have influenced its design:
- Progressive Buffer Allocation.
- Parametric Tiling.
- Promotion to Temporary Buffer in Fast Memory.
- Tiled Producer-Consumer Fusion with Parametric Tile-And-Fuse.
- Map to Parallel and Reduction Loops and Hardware.
- Vectorization: Rewrite in Vector Form.
- Lower to Loops (Affine, Generic, and Parallel).
- Lower to Library Calls or Special Instructions, Intrinsics or ISA.
- Partially Lower to Iterations Over a Finer-Grained Linalg Op.
High-Level Description of Linalg Ops
Linalg takes at least some inspiration from all previously listed prior art. The design enables the definition of CustomOps with generic properties that enable key transformations, including lowering to scalar load/store and other operations or to external library calls and intrinsics.
These ops can have either tensor or buffer as both input and output operands. Output tensors operands serve the purpose of providing a unifying abstraction and give a shape to the results. Output tensors can come in 2 flavors and are always associated with a corresponding op result:
an “init tensor” output value which provides an initial value for a tensor that is created by iteratively updating the result (also called “destructive updates”). Such tensor is always materialized in some form. If enough fusion occurs it may end up being materialized only as a register-level SSA value. It is expected (but not required) that the destructive update pattern can be rewritten as an inplace update on buffers.
a “shape-only” tensor output value whose underlying elements are not used in the payload computation and only serves the purpose of carrying shape information to lower levels of abstraction. In the future this will be replaced by an appropriate shape type when it is available as a builtin type (see the discourse discussion Linalg and Shapes for more details).
Payload-Carrying Ops
Linalg defines a payload carrying operation that implements the
structured op
abstraction on tensors and buffers. This linalg.generic operation can express
custom operations that optionally have indexing semantics (by accessing the
iteration indices using the linalg.index operation). The properties of
linalg.generic are the result of applying the guiding principles described in
the
Rationale Document. They are
listed next, with a brief example and discussion for each.
Property 1: Input and Output Operands Define The Iteration Space
A linalg.generic op fully derives the specification of its iteration space
from its operands. The property enforces that a localized IR element (the op)
has all the information needed to synthesize the control-flow required to
iterate over its operands, according to their type. This notion of IR
localization bears some resemblance to
URUK.
Consider the following fully specified linalg.generic example. Here, the first
operand is a memref of f32 scalar elements that has an ordinary identity
layout, and the second one is a memref of 4-element vectors with a 2-strided,
1-offset layout.
// File name: example1.mlir
#accesses = [
affine_map<(m) -> (m)>,
affine_map<(m) -> (m)>
]
#attrs = {
indexing_maps = #accesses,
iterator_types = ["parallel"]
}
func.func @example(%A: memref<?xf32, strided<[1]>>,
%B: memref<?xvector<4xf32>, strided<[2], offset: 1>>) {
linalg.generic #attrs
ins(%A: memref<?xf32, strided<[1]>>)
outs(%B: memref<?xvector<4xf32>, strided<[2], offset: 1>>) {
^bb0(%a: f32, %b: vector<4xf32>):
%c = "some_compute"(%a, %b): (f32, vector<4xf32>) -> (vector<4xf32>)
linalg.yield %c: vector<4xf32>
}
return
}
The property “Input and Output Operands Define The Iteration Space” is materialized by a lowering into a form that will resemble:
// Run: mlir-opt example1.mlir -allow-unregistered-dialect -convert-linalg-to-loops
// This converted representation is in the `scf` dialect.
// It's syntax can be found here: https://mlir.llvm.org/docs/Dialects/SCFDialect/
func.func @example(%arg0: memref<?xf32>,
%arg1: memref<?xvector<4xf32>, strided<[2], offset: 1>>) {
%c0 = arith.constant 0 : index
%c1 = arith.constant 1 : index
%0 = memref.dim %arg0, %c0 : memref<?xf32>
scf.for %arg2 = %c0 to %0 step %c1 {
%1 = memref.load %arg0[%arg2] : memref<?xf32>
%2 = memref.load %arg1[%arg2]
: memref<?xvector<4xf32>, strided<[2], offset: 1>>
%3 = "some_compute"(%1, %2) : (f32, vector<4xf32>) -> vector<4xf32>
memref.store %3, %arg1[%arg2]
: memref<?xvector<4xf32>, strided<[2], offset: 1>>
}
return
}
The property participates in simplifying analyses and transformations. For
instance, it guarantees no out-of bounds access can occur by construction
(assuming dynamic operand dimensions agree with each other, which is the purpose
of the assert runtime check).
Before lowering to loop form, loop induction variables and iterators are implicit (i.e. not yet materialized).
The main implications are that:
The semantics of the ops are restricted to operate on structured data types, on which we can define an iterator.
This does not model arbitrary code with side-effects.
We do not think these are serious limitations in practice because MLIR is all about mixing different levels of abstractions in the same IR. As long as Linalg can progressively lower to the next level of abstraction, it can also be just bypassed for things that do not fit.
At the same time, conditioning op semantics on structured data types is a very promising path towards extensibility to non-dense tensors as experience with LIFT abstractions for sparse and position-dependent arrays, as well as TACO, has shown.
Property 2: Reversible Mappings Between Control and Data Structures
A linalg.generic defines the mapping between the iteration space (i.e. the
loops) and the data.
Consider the following fully specified linalg.generic example. Here, the first
memref is a 2-strided one on both of its dimensions, and the second memref
uses an identity layout.
// File name: example2.mlir
#indexing_maps = [
affine_map<(i, j) -> (j, i)>,
affine_map<(i, j) -> (j)>
]
#attrs = {
indexing_maps = #indexing_maps,
iterator_types = ["parallel", "parallel"]
}
func.func @example(%A: memref<8x?xf32, strided<[2, 2], offset: 0>>,
%B: memref<?xvector<4xf32>>) {
linalg.generic #attrs
ins(%A: memref<8x?xf32, strided<[2, 2], offset: 0>>)
outs(%B: memref<?xvector<4xf32>>) {
^bb0(%a: f32, %b: vector<4xf32>):
%c = "some_compute"(%a, %b): (f32, vector<4xf32>) -> (vector<4xf32>)
linalg.yield %c: vector<4xf32>
}
return
}
The property “Reversible Mappings Between Control and Data Structures” is materialized by a lowering into a form that will resemble:
// Run: mlir-opt example2.mlir -allow-unregistered-dialect -convert-linalg-to-loops
func.func @example(%arg0: memref<8x?xf32, strided<[2, 2]>>, %arg1: memref<?xvector<4xf32>>) {
%c8 = arith.constant 8 : index
%c0 = arith.constant 0 : index
%c1 = arith.constant 1 : index
%0 = memref.dim %arg0, %c1 : memref<8x?xf32, strided<[2, 2]>>
scf.for %arg2 = %c0 to %0 step %c1 {
scf.for %arg3 = %c0 to %c8 step %c1 {
%1 = memref.load %arg0[%arg3, %arg2] : memref<8x?xf32, strided<[2, 2]>>
%2 = memref.load %arg1[%arg3] : memref<?xvector<4xf32>>
%3 = "some_compute"(%1, %2) : (f32, vector<4xf32>) -> vector<4xf32>
memref.store %3, %arg1[%arg3] : memref<?xvector<4xf32>>
}
}
return
}
This mapping needs to be reversible because we want to be able to go back and forth between the two and answer questions such as:
- Given a subset of the iteration space, what subset of data does it read and write?
- Given a subset of data read or written, what subset of the iteration space is responsible for this read or write?
Answering these 2 questions is one of the main analyses that Linalg uses to
implement transformations such as tiling, tiled producer-consumer fusion, and
promotion to temporary buffers in fast memory.
In the current implementation, linalg.generic uses a list of
AffineMaps (see the
#indexing_maps attribute in the previous examples). This is a pragmatic
short-term solution, but in the longer term note that this property could be
even evaluated dynamically, similarly to inspector-executor algorithms.
Property 3: The Type Of Iterators is Defined Explicitly
A linalg.generic op fully declares the type of its iterators. This
information is used in transformations.
These properties are derived from established practice in the field and mirror the properties from Ken Kennedy’s Optimizing Compilers for Modern Architectures. The key idea of legality of loop transformations expressed by Kennedy is that the lexicographic order of all dependence vectors must be preserved.
This can be better captured directly at the loop level thanks to specific iterator types, among which: parallel, reduction, partition, permutable/monotonic, sequential, dependence distance, …
These types are traditionally the result of complex dependence analyses and have been referred to as “bands” in the polyhedral community (e.g. parallel bands, permutable bands, etc, in ISL schedule tree parlance).
Specifying the information declaratively in a linalg.generic allows conveying
properties that may be hard (or even impossible) to derive from lower-level
information. These properties can be brought all the way to the moment when they
are useful for transformations, used and then discarded.
Additionally, these properties may also be viewed as a contract that the frontend/user guarantees and that the compiler may take advantage of. The common example is the use of data-dependent reduction semantics for specifying histogram computations. If the frontend has additional knowledge that proper atomic operations are available, it may be better to specify parallel semantics and use the special atomic in the computation region.
At this time, Linalg only has an explicit use for parallel and reduction loops but previous experience shows that the abstraction generalizes.
Property 4: The Compute Payload is Specified With a Region
A linalg.generic op has a compute payload that is fully generic thanks to the
use of
Regions.
The region takes as arguments the scalar elemental types of the tensor or buffer
operands of the linalg.generic. For flexibility and ability to match library
calls, additional special values may be passed. For instance, a linalg.fill
operation takes a buffer and an additional scalar value.
At this time there are no additional restrictions to the region semantics. This is meant to allow the exploration of various design tradeoffs at the intersection of regions and iterator types. In particular, the frontend is responsible for the semantics of iterator types to correspond to the operations inside the region: the region can capture buffers arbitrarily and write into them. If this conflicts with some parallel iterator requirement, this is undefined behavior.
Previous examples already elaborate compute payloads with an unregistered
function "some_compute". The following code snippet shows what the result will
be when using a concrete operation addf:
// File name: example3.mlir
#map = affine_map<(i, j) -> (i, j)>
#attrs = {
indexing_maps = [#map, #map, #map],
iterator_types = ["parallel", "parallel"]
}
func.func @example(%A: memref<?x?xf32>, %B: memref<?x?xf32>, %C: memref<?x?xf32>) {
linalg.generic #attrs
ins(%A, %B: memref<?x?xf32>, memref<?x?xf32>)
outs(%C: memref<?x?xf32>) {
^bb0(%a: f32, %b: f32, %c: f32):
%d = arith.addf %a, %b : f32
linalg.yield %d : f32
}
return
}
This function basically element-wise adds up two matrices (%A and %B) and
stores the result into another one (%C).
The property “The Compute Payload is Specified With a Region” is materialized by a lowering into a form that will resemble:
func.func @example(%arg0: memref<?x?xf32>, %arg1: memref<?x?xf32>, %arg2: memref<?x?xf32>) {
%c0 = arith.constant 0 : index
%c1 = arith.constant 1 : index
%0 = memref.dim %arg0, %c0 : memref<?x?xf32>
%1 = memref.dim %arg0, %c1 : memref<?x?xf32>
scf.for %arg3 = %c0 to %0 step %c1 {
scf.for %arg4 = %c0 to %1 step %c1 {
%2 = memref.load %arg0[%arg3, %arg4] : memref<?x?xf32>
%3 = memref.load %arg1[%arg3, %arg4] : memref<?x?xf32>
%4 = arith.addf %2, %3 : f32
memref.store %4, %arg2[%arg3, %arg4] : memref<?x?xf32>
}
}
return
}
In the process of lowering to loops and lower-level constructs, similar requirements are encountered, as are discussed in the inlined call op proposal. We expect to be able to reuse the common lower-level infrastructure provided it evolves to support both region arguments and captures.
Property 5: May Map To an External Library Call
A linalg.generic op may map to an external library call by specifying a
SymbolAttr. At this level of abstraction, the important glue is the ability to
perform transformations that preserve the structure necessary to call the
external library after different transformations have been applied.
This involves considerations related to preservation of op semantics and integration at the ABI level. Regardless of whether one wants to use external library calls or a custom ISA, the problem for codegen is similar: preservation of a fixed granularity.
Consider the following example that adds an additional attribute
library_call="pointwise_add" that specifies the name of an external library
call we intend to use:
// File name: example4.mlir
#indexing_maps = [
affine_map<(i, j) -> (i, j)>,
affine_map<(i, j) -> (i, j)>,
affine_map<(i, j) -> (i, j)>
]
#attrs = {
indexing_maps = #indexing_maps,
iterator_types = ["parallel", "parallel"],
library_call = "pointwise_add"
}
func.func @example(%A: memref<?x?xf32>, %B: memref<?x?xf32>, %C: memref<?x?xf32>) {
linalg.generic #attrs
ins(%A, %B: memref<?x?xf32>, memref<?x?xf32>)
outs(%C: memref<?x?xf32>) {
^bb0(%a: f32, %b: f32, %c: f32):
%d = arith.addf %a, %b : f32
linalg.yield %d : f32
}
return
}
The property “Map To an External Library Call” is materialized by a lowering into a form that will resemble:
// Run: mlir-opt example4.mlir -convert-linalg-to-std
func.func @example(%arg0: memref<?x?xf32>, %arg1: memref<?x?xf32>, %arg2: memref<?x?xf32>) {
%0 = memref.cast %arg0 : memref<?x?xf32> to memref<?x?xf32, strided<[?, ?], offset: ?>>
%1 = memref.cast %arg1 : memref<?x?xf32> to memref<?x?xf32, strided<[?, ?], offset: ?>>
%2 = memref.cast %arg2 : memref<?x?xf32> to memref<?x?xf32, strided<[?, ?], offset: ?>>
call @pointwise_add(%0, %1, %2) : (memref<?x?xf32, strided<[?, ?], offset: ?>>,
memref<?x?xf32, strided<[?, ?], offset: ?>>, memref<?x?xf32, strided<[?, ?], offset: ?>>) -> ()
return
}
func.func @pointwise_add(memref<?x?xf32, strided<[?, ?], offset: ?>>,
memref<?x?xf32, strided<[?, ?], offset: ?>>,
memref<?x?xf32, strided<[?, ?], offset: ?>>) attributes {llvm.emit_c_interface}
Which, after lowering to LLVM resembles:
// Run: mlir-opt example4.mlir -convert-linalg-to-std | mlir-opt -convert-func-to-llvm
// Some generated code are omitted here.
func.func @example(%arg0: !llvm<"float*">, ...) {
...
llvm.call @pointwise_add(...) : (!llvm<"float*">, ...) -> ()
return
}
llvm.func @pointwise_add(%arg0: !llvm<"float*">, ...) attributes {llvm.emit_c_interface} {
...
llvm.call @_mlir_ciface_pointwise_add(%9, %19, %29) : (!llvm."{ float*, float*, i64, [2 x i64], [2 x i64] }*">, !llvm<"{ f32*, f32*, i64, [2 x i64], [2 x i64] }*">, !llvm<"{ float*, float*, i64, [2 x i64], [2 x i64] }
*">) -> ()
llvm.return
}
llvm.func @_mlir_ciface_pointwise_add(!llvm."{ float*, float*, i64, [2 x i64], [2 x i64] }*">, !llvm<"{ f32*, f32*, i64, [2 x i64], [2 x i64] }*">, !llvm<"{ f32*, f32*, i64, [2 x i64], [2 x i64] }*">) attributes {llvm.emit_c_interface}
Convention For External Library Interoperability
The linalg dialect adopts a convention that is similar to BLAS when
offloading operations to fast library implementations: pass a non-owning pointer
to input and output data with additional metadata. This convention is also found
in libraries such as MKL, OpenBLAS, BLIS, cuBLAS, cuDNN, etc.. and
more generally at interface points across language boundaries (e.g. C++ /
Python).
Generally, linalg passes non-owning pointers to View data structures to
pre-compiled library calls linked externally.
There is an ongoing discussion on the topic of extending interoperability in the presence of key attributes.
Property 6: Perfectly Nested Writes To The Whole Output Operands
Perfectly nested loops form a particularly important class of structure that enables key loop transformations such as tiling and mapping to library calls. Unfortunately, this type of structure is easily broken by transformations such as partial loop fusion. Tiling and mapping to library calls become more challenging, or even infeasible. Linalg ops adopt perfect-nestedness as a first-class property: the structure cannot be broken and is transported in the IR by construction.
A linalg.generic op represents a perfectly nested loop nest that writes the
entire memory region. This is a structural constraint across regions and loops
that has proven to be key in simplifying transformations.
One particular point to mention is that converting imperfectly nested code into perfectly nested code can often be done with enough loop distribution and embedding of conditionals down to the innermost loop level.
Previous experience with Tensor Comprehensions gave us the intuition that forcing innermost control-flow nesting is a lot like writing data-parallel code with arrays of boolean values and predication. This type of trick has also been used before in polyhedral compilers to convert non-affine control into affine compute dependencies.
While it may be possible to automate such rewrites from generic IR,
linalg.generic just forces the semantics for now.
The key implication is that this conversion to deep predication needs to be
undone once we are done with Linalg transformations. After iterators and
induction variables are materialized (i.e. after lowering out of
linalg.generic occurred), the overall performance will be greatly influenced
by the quality of canonicalizations, foldings and Loop Independent Code Motion
(LICM).
In the grander scheme, the reliance on late LICM was deemed a necessary risk.
Putting it Together
As it stands, the six properties above define the semantics of a
linalg.generic op. It is an open question whether all of these semantics are
strictly necessary in practice and whether some should or could be derived
automatically while still maintaining the
core guiding principles.
For the time being, we have settled on the combination of these properties because of empirical evidence building and working on multiple high-level compilers. As we lay those down and engage more with the community, we expect multiple rounds of discussions and design changes to the original architecture.
Data Representation: Views
The current implementation uses the
Strided MemRef (a.k.a View)
abstraction. The name View is used interchangeably in linalg to signify
Strided MemRef. In the future we expect to use other structured data types and
support ragged, mixed-sparse and other types. We expect to draw on the
experience from existing LIFT abstractions for
sparse and
position-dependent arrays.
Metadata Ops
A set of ops that manipulate metadata but do not move memory. These ops take
view operands + extra attributes and return new views. The returned views
generally alias the operand view. At the moment the existing ops are:
* `memref.view`,
* `memref.subview`,
* `memref.transpose`.
* `linalg.slice`,
* `linalg.reshape`,
Future ops are added on a per-need basis but should include:
* `linalg.tile`,
* `linalg.intersection`,
* `linalg.convex_union`,
* `linalg.difference` (would need to work on a list of views).
These additional operations correspond to abstractions that have been known to work in the field of large-scale distributed stencil computations.
In a longer-term future, the abstractions from Legion data-centric programming model seem generally appealing.
Named Payload-Carrying Ops
Additionally, linalg provides a small subset of commonly named operations:
* `linalg.fill`,
* `linalg.dot`,
* `linalg.matmul`,
* `linalg.conv`.
These named operations adhere to the linalg.generic op interface. Work is in
progress to define declarative mechanisms to automatically generate named ops
from a description in terms of only the generic op interface.
This is the main reason there are only a small number of ops today: we expect them to be auto-generated from Tablegen soon.
Named Payload Ops Specification
Linalg provides a declarative specification and a generation tool
(mlir-linalg-ods-gen) to automatically produce named ops from a notation that
is inspired by Einstein notation.
The syntax and semantics used in mlir-linalg-ods-gen are very much in flight
and borrow from Tensor Comprehensions (TC) but differ in a few dimensions, to
better adapt to Linalg:
- The input and output tensor parameters are specified as
id : type(symbolic-affine-expression-list)(e.g.A : f32(M, N + M)) and each new symbol is discovered eagerly. TC on the other hand does not allow general symbolic affine expressions. - The output shapes are specified explicitly, in TC they are always derived from the input shapes.
- The operations used to specify computations use EDSC intrinsics so that they can easily be parsed and emitted into a simple region builder without resorting to more general MLIR parsing.
- Reduction dimensions are specified with angle bracket notation on the
operation they apply to (e.g.
std_add<k>specifies thatkis a reduction dimension). In TC, the reduction dimensions are inferred. If one of the operand is not used in any expressions, it will be considered a shape-only operand, and the result of the indexing_map will be reduction dimensions. - The parallel and reduction dimension are ordered by the textual program
order. For instance, in the comprehension
O(i, j) = std_add<k, l>(...),i(resp.j) is a parallel iterator encoded by affine dimension of position0(resp.1);k(resp.l) is a reduction iterator encoded by an affine dimension of position2(resp.3). - A list of attributes can be defined for the op with the format of
attr( strides: 2xi32)and referenced in comprehension likestrides[0]. These attribute uses will be parsed as affine symbols to generate op definition and implementation. For a concrete op instance, the runtime constant values from the attributes will be used to replace the affine symbols and simplify the indexing maps.
These decisions and syntax are subject to evolution and change. In particular, op-specific attributes, dynamic ranks, some form of templating, shape calculation function specification, etc. may be added in the future.
At this time, the following restrictions are imposed on the syntax and semantics:
- Each def may only contain a single comprehension but each comprehension may perform multiple updates.
- Each tensor may only be used with a single indexing expression.
A """-wrapped doc string can be attached to the named op. It should contain a
oneliner for summary first, followed by lengthy description.
The following specification may be used to define a named batchmatmul op:
def batchmatmul(A: f32(Batch, M, K), B: f32(K, N)) -> (C: f32(Batch, M, N))
"""Batch matrix-multiply operation.
This operation performs batch matrix-multiply over ...
"""
{
C(b, m, n) = std_addf<k>(std_mulf(A(b, m, k), B(k, n)));
}
When mlir-linalg-ods-gen -gen-ods-decl=1 is called, the following ODS is
produced:
def batchmatmulOp : LinalgNamedStructured_Op<"batchmatmul", [
NInputs<2>,
NOutputs<1>,
NamedStructuredOpTrait]> { ... }
When mlir-linalg-ods-gen -gen-impl=1 is called, the following C++ is produced:
std::optional<SmallVector<StringRef, 8>> batchmatmul::referenceIterators() {
return SmallVector<StringRef, 8>{
getParallelIteratorTypeName(),
getParallelIteratorTypeName(),
getParallelIteratorTypeName(),
getReductionIteratorTypeName() };
}
std::optional<SmallVector<AffineMap, 8>> batchmatmul::referenceIndexingMaps() {
MLIRContext *context = getContext();
AffineExpr d0, d1, d2, d3;
bindDims(context, d0, d1, d2, d3);
return SmallVector<AffineMap, 8>{
AffineMap::get(4, 0, {d0, d1, d3}),
AffineMap::get(4, 0, {d3, d2}),
AffineMap::get(4, 0, {d0, d1, d2}) };
}
void batchmatmul::regionBuilder(ArrayRef<BlockArgument> args) {
using namespace edsc;
using namespace intrinsics;
Value _0(args[0]), _1(args[1]), _2(args[2]);
Value _4 = std_mulf(_0, _1);
Value _5 = std_addf(_2, _4);
(linalg_yield(ValueRange{ _5 }));
}
YAML Based Named Structured Ops
Linalg provides a declarative generation tool (mlir-linalg-ods-yaml-gen) to
automatically produce named ops from a YAML-based op description format intended
to capture the structure of the named ops. The YAML-based op descriptions are
generated from a higher level
DSL and are not meant to be edited
directly.
This facility is currently in flight and is intended to subsume the above when
ready. See the C++ class to YAML mapping traits in
mlir-linalg-ods-yaml-gen.cpp as the source of truth for the schema.
Most of the above documentation roughly applies to this path and will be ported as migration continues.
Open Issues and Design Alternatives
Multiple open issues and design alternatives are in flight and it is time to lay them out for the community to discuss and pick apart:
- Should
linalg.genericsupport nesting? - Should
linalg.genericregions take views or only scalars? - Should we try to solve automatic differentiation at this level of abstraction?
- Are all the six properties really necessary?
- Is this relying too much on declarative specification and would we be better off relying more on analyses?
- Is this general enough for the community’s needs? If not how should this be extended, if at all? …
These key questions (and much more) should be really thought of in the general context of MLIR in which different levels of IR interoperate seamlessly. In practice, it is not necessary (or beneficial) to try and solve all problems in the same IR.
Operations
linalg.abs (linalg::AbsOp)
Applies abs(x) elementwise.
No numeric casting is performed on the input operand.
Traits: AttrSizedOperandSegments, RecursiveMemoryEffects, SingleBlockImplicitTerminator<YieldOp>, SingleBlock
Interfaces: ConditionallySpeculatable, DestinationStyleOpInterface, IndexingMapOpInterface, LinalgStructuredInterface, MemoryEffectOpInterface, ReifyRankedShapedTypeOpInterface
Operands:
| Operand | Description |
|---|---|
inputs | variadic of any non-token type |
outputs | variadic of shaped of any non-token type values |
Results:
| Result | Description |
|---|---|
result_tensors | variadic of ranked tensor of any non-token type values |
linalg.add (linalg::AddOp)
Adds two tensors elementwise.
The shapes and element types must be identical. The appropriate casts, broadcasts and reductions should be done previously to calling this op.
This means reduction/broadcast/element cast semantics is explicit. Further
passes can take that into account when lowering this code. For example,
a linalg.broadcast + linalg.add sequence can be lowered to a
linalg.generic with different affine maps for the two operands.
Traits: AttrSizedOperandSegments, RecursiveMemoryEffects, SingleBlockImplicitTerminator<YieldOp>, SingleBlock
Interfaces: ConditionallySpeculatable, DestinationStyleOpInterface, IndexingMapOpInterface, LinalgStructuredInterface, MemoryEffectOpInterface, ReifyRankedShapedTypeOpInterface
Operands:
| Operand | Description |
|---|---|
inputs | variadic of any non-token type |
outputs | variadic of shaped of any non-token type values |
Results:
| Result | Description |
|---|---|
result_tensors | variadic of ranked tensor of any non-token type values |
linalg.batch_matmul (linalg::BatchMatmulOp)
Performs a batched matrix multiplication of two 3D inputs.
Numeric casting is performed on the operands to the inner multiply, promoting them to the same data type as the accumulator/output.
Broadcast and Transpose semantics can be appiled by specifying the explicit attribute
'indexing_maps' as shown below. This is a list attribute, so must include maps for all
arguments if specified.
Example Transpose:
```mlir
linalg.batch_matmul
indexing_maps = [affine_map<(batch, m, n, k) -> (batch, k, m)>, // transpose
affine_map<(batch, m, n, k) -> (batch, k, n)>,
affine_map<(batch, m, n, k) -> (batch, m, n)>]
ins(%arg0, %arg1 : memref<2x5x3xf32>,memref<2x5x7xf32>)
outs(%arg2: memref<2x3x7xf32>)
```
Example Broadcast:
```mlir
linalg.batch_matmul
indexing_maps = [affine_map<(batch, m, n, k) -> (k)>, // broadcast
affine_map<(batch, m, n, k) -> (batch, k, n)>,
affine_map<(batch, m, n, k) -> (batch, m, n)>]
ins(%arg0, %arg1 : memref<5xf32>, memref<2x5x7xf32>)
outs(%arg2: memref<2x3x7xf32>)
```
Example Broadcast and Transpose:
```mlir
linalg.batch_matmul
indexing_maps = [affine_map<(batch, m, n, k) -> (m, k)>, // broadcast
affine_map<(batch, m, n, k) -> (batch, n, k)>, // transpose
affine_map<(batch, m, n, k) -> (batch, m, n)>]
ins(%arg0, %arg1 : memref<3x5xf32>, memref<2x7x5xf32>)
outs(%arg2: memref<2x3x7xf32>)
```
Traits: AttrSizedOperandSegments, RecursiveMemoryEffects, SingleBlockImplicitTerminator<YieldOp>, SingleBlock
Interfaces: ConditionallySpeculatable, DestinationStyleOpInterface, IndexingMapOpInterface, LinalgContractionOpInterface, LinalgStructuredInterface, MemoryEffectOpInterface, ReifyRankedShapedTypeOpInterface
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
indexing_maps | ::mlir::ArrayAttr | AffineMap array attribute |
cast | ::mlir::linalg::TypeFnAttr | allowed 32-bit signless integer cases: 0, 1 |
Operands:
| Operand | Description |
|---|---|
inputs | variadic of any non-token type |
outputs | variadic of shaped of any non-token type values |
Results:
| Result | Description |
|---|---|
result_tensors | variadic of ranked tensor of any non-token type values |
linalg.batch_matvec (linalg::BatchMatvecOp)
Performs a batched matrix-vector multiplication.
Numeric casting is performed on the operands to the inner multiply, promoting them to the same data type as the accumulator/output.
Traits: AttrSizedOperandSegments, RecursiveMemoryEffects, SingleBlockImplicitTerminator<YieldOp>, SingleBlock
Interfaces: ConditionallySpeculatable, DestinationStyleOpInterface, IndexingMapOpInterface, LinalgContractionOpInterface, LinalgStructuredInterface, MemoryEffectOpInterface, ReifyRankedShapedTypeOpInterface
Operands:
| Operand | Description |
|---|---|
inputs | variadic of any non-token type |
outputs | variadic of shaped of any non-token type values |
Results:
| Result | Description |
|---|---|
result_tensors | variadic of ranked tensor of any non-token type values |
linalg.batch_mmt4d (linalg::BatchMmt4DOp)
Performs a batched matrix-matrix-transpose multiplication of two batched-4D (5D) inputs.
Besides the outermost batch dimension has the same semantic as linalg.batch_matmul, the differences from linalg.batch_matmul in the non-batch dimensions are the same as linalg.mmt4d vs. linalg.matmul. See the description of lingalg.mmt4d.
Traits: AttrSizedOperandSegments, RecursiveMemoryEffects, SingleBlockImplicitTerminator<YieldOp>, SingleBlock
Interfaces: ConditionallySpeculatable, DestinationStyleOpInterface, IndexingMapOpInterface, LinalgContractionOpInterface, LinalgStructuredInterface, MemoryEffectOpInterface, ReifyRankedShapedTypeOpInterface
Operands:
| Operand | Description |
|---|---|
inputs | variadic of any non-token type |
outputs | variadic of shaped of any non-token type values |
Results:
| Result | Description |
|---|---|
result_tensors | variadic of ranked tensor of any non-token type values |
linalg.batch_reduce_matmul (linalg::BatchReduceMatmulOp)
Performs a batch-reduce matrix multiplication on two inputs. The partial multiplication results are reduced into a 2D output.
Numeric casting is performed on the operands to the inner multiply, promoting them to the same data type as the accumulator/output.
Broadcast and Transpose semantics can be applied by specifying the explicit attribute ‘indexing_maps’ as shown below. This is a list attribute, so must include maps for all arguments if specified.
Example Transpose:
linalg.batch_reduce_matmul
indexing_maps = [affine_map<(batch, m, n, k) -> (batch, k, m)>, // transpose
affine_map<(batch, m, n, k) -> (batch, k, n)>,
affine_map<(batch, m, n, k) -> (m, n)>]
ins(%arg0, %arg1 : memref<2x5x3xf32>,memref<2x5x7xf32>)
outs(%arg2: memref<3x7xf32>)
Example Broadcast:
linalg.batch_reduce_matmul
indexing_maps = [affine_map<(batch, m, n, k) -> (k)>, // broadcast
affine_map<(batch, m, n, k) -> (batch, k, n)>,
affine_map<(batch, m, n, k) -> (m, n)>]
ins(%arg0, %arg1 : memref<5xf32>, memref<2x5x7xf32>)
outs(%arg2: memref<3x7xf32>)
Example Broadcast and Transpose:
linalg.batch_reduce_matmul
indexing_maps = [affine_map<(batch, m, n, k) -> (m, k)>, // broadcast
affine_map<(batch, m, n, k) -> (batch, n, k)>, // transpose
affine_map<(batch, m, n, k) -> (m, n)>]
ins(%arg0, %arg1 : memref<3x5xf32>, memref<2x7x5xf32>)
outs(%arg2: memref<3x7xf32>)
Traits: AttrSizedOperandSegments, RecursiveMemoryEffects, SingleBlockImplicitTerminator<YieldOp>, SingleBlock
Interfaces: ConditionallySpeculatable, DestinationStyleOpInterface, IndexingMapOpInterface, LinalgContractionOpInterface, LinalgStructuredInterface, MemoryEffectOpInterface, ReifyRankedShapedTypeOpInterface
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
indexing_maps | ::mlir::ArrayAttr | AffineMap array attribute |
cast | ::mlir::linalg::TypeFnAttr | allowed 32-bit signless integer cases: 0, 1 |
Operands:
| Operand | Description |
|---|---|
inputs | variadic of any non-token type |
outputs | variadic of shaped of any non-token type values |
Results:
| Result | Description |
|---|---|
result_tensors | variadic of ranked tensor of any non-token type values |
linalg.batch_vecmat (linalg::BatchVecmatOp)
Performs a batched matrix-vector multiplication.
Numeric casting is performed on the operands to the inner multiply, promoting them to the same data type as the accumulator/output.
Traits: AttrSizedOperandSegments, RecursiveMemoryEffects, SingleBlockImplicitTerminator<YieldOp>, SingleBlock
Interfaces: ConditionallySpeculatable, DestinationStyleOpInterface, IndexingMapOpInterface, LinalgContractionOpInterface, LinalgStructuredInterface, MemoryEffectOpInterface, ReifyRankedShapedTypeOpInterface
Operands:
| Operand | Description |
|---|---|
inputs | variadic of any non-token type |
outputs | variadic of shaped of any non-token type values |
Results:
| Result | Description |
|---|---|
result_tensors | variadic of ranked tensor of any non-token type values |
linalg.broadcast (linalg::BroadcastOp)
Static broadcast operator
Broadcast the input into the given shape by adding dimensions.
Each index in the dimensions attribute refers to a dimension of init
that is added by the operation. The indices must be unique and within the
rank of init; the sizes of the remaining (non-added) dimensions of
init must match the shape of input.
Example:
%bcast = linalg.broadcast
ins(%input:tensor<16xf32>)
outs(%init:tensor<16x64xf32>)
dimensions = [1]
Traits: RecursiveMemoryEffects, SingleBlockImplicitTerminator<YieldOp>, SingleBlock
Interfaces: ConditionallySpeculatable, DestinationStyleOpInterface, IndexingMapOpInterface, LinalgStructuredInterface, MemoryEffectOpInterface, OpAsmOpInterface, ReifyRankedShapedTypeOpInterface
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
dimensions | ::mlir::DenseI64ArrayAttr | i64 dense array attribute |
Operands:
| Operand | Description |
|---|---|
input | memref of any non-token type values or ranked tensor of any non-token type values |
init | memref of any non-token type values or ranked tensor of any non-token type values |
Results:
| Result | Description |
|---|---|
result | variadic of tensor of any non-token type values |
linalg.ceil (linalg::CeilOp)
Applies ceil(x) elementwise.
No numeric casting is performed on the input operand.
Traits: AttrSizedOperandSegments, RecursiveMemoryEffects, SingleBlockImplicitTerminator<YieldOp>, SingleBlock
Interfaces: ConditionallySpeculatable, DestinationStyleOpInterface, IndexingMapOpInterface, LinalgStructuredInterface, MemoryEffectOpInterface, ReifyRankedShapedTypeOpInterface
Operands:
| Operand | Description |
|---|---|
inputs | variadic of any non-token type |
outputs | variadic of shaped of any non-token type values |
Results:
| Result | Description |
|---|---|
result_tensors | variadic of ranked tensor of any non-token type values |
linalg.contract (linalg::ContractOp)
Perform a contraction on two inputs, accumulating into the third.
The semantics of contracting inputs A and B on top of C to produce
output D is given by
D[H] = (SUM_{(I ∪ J) \ H} A[I] * B[J]) + C[H]
where I, J, and H are tuples of (pairwise distinct) dimension
identifiers - meant to range over valid indices - corresponding to the
results of the mandatory (projected permutation) indexing_maps for A,
B and C. SUM_{dims} means reduce over all valid indices for the
dimensions in the set dims (with I, J, and K treated as sets of
dim identifiers).
The iteration space consists of all dimensions in I, J and H, i.e. the
domain of each of the affine_maps. Like for einsums, the iteration type of
each dim is inferred and is either:
reduction: the dim is used to index into
AandBbut notC. Per the above semantics, these dims will be contracted, i.e. reduced over.parallel: the dim is used to index into
Cand at least one ofAandB, and - deriving from matmul terminology - is either an “M-like” dim (if used onAandC), an “N-like” dim (if used onBandC) or a “batch”-dim (if used to index intoA,B, andC).
For example, batch-matmul is given by I = ⟨ b, m, k ⟩, J = ⟨ b, k, n ⟩,
H = ⟨ b, m, n ⟩ (with k as a contracting reduction-dimension while m,
n and b have parallel iteration-type) and gets represented as:
%D = linalg.contract
indexing_maps = [affine_map<(batch, m, n, k) -> (batch, m, k)>,
affine_map<(batch, m, n, k) -> (batch, k, n)>,
affine_map<(batch, m, n, k) -> (batch, m, n)>]
ins(%A, %B: tensor<?x?x?xf32>, tensor<?x?x?xf32>)
outs(%C: tensor<?x?x?xf32>) -> tensor<?x?x?xf32>
Note that by permuting dims in the affine_maps’ results, accesses to
to the inputs and output can be arbitrarily transposed. Similarly, arbitrary
broadcasts can be achieved through leaving out dims on either input operand.
For example, the following is a variant of batch-matmul with a transposition
applied to A while B’s 2D-matrix gets broadcasted along the batch dim:
linalg.contract
indexing_maps = [affine_map<(batch, m, n, k) -> (batch, k, m)>,
affine_map<(batch, m, n, k) -> (k, n)>,
affine_map<(batch, m, n, k) -> (batch, m, n)>]
ins(%A, %B: memref<?x?x?xf32>, memref<?x?xf32>)
outs(%C: memref<?x?x?xf32>)
Numeric casting is performed on the operands to the inner multiplication, promoting/truncating them to the same data type as the accumulator/output.
TODO: Allow control over the combining/accumulating op and possibly the multiplication op.
Traits: AttrSizedOperandSegments, RecursiveMemoryEffects, SingleBlockImplicitTerminator<YieldOp>, SingleBlock
Interfaces: ConditionallySpeculatable, DestinationStyleOpInterface, IndexingMapOpInterface, LinalgContractionOpInterface, LinalgStructuredInterface, MemoryEffectOpInterface, ReifyRankedShapedTypeOpInterface
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
indexing_maps | ::mlir::ArrayAttr | AffineMap array attribute |
cast | ::mlir::linalg::TypeFnAttr | allowed 32-bit signless integer cases: 0, 1 |
Operands:
| Operand | Description |
|---|---|
inputs | variadic of any non-token type |
outputs | variadic of shaped of any non-token type values |
Results:
| Result | Description |
|---|---|
result_tensors | variadic of ranked tensor of any non-token type values |
linalg.conv_1d (linalg::Conv1DOp)
Performs 1-D convolution with no channels.
Numeric casting is performed on the operands to the inner multiply, promoting them to the same data type as the accumulator/output.
Traits: AttrSizedOperandSegments, RecursiveMemoryEffects, SingleBlockImplicitTerminator<YieldOp>, SingleBlock
Interfaces: ConditionallySpeculatable, DestinationStyleOpInterface, IndexingMapOpInterface, LinalgConvolutionOpInterface, LinalgStructuredInterface, MemoryEffectOpInterface, ReifyRankedShapedTypeOpInterface
Operands:
| Operand | Description |
|---|---|
inputs | variadic of any non-token type |
outputs | variadic of shaped of any non-token type values |
Results:
| Result | Description |
|---|---|
result_tensors | variadic of ranked tensor of any non-token type values |
linalg.conv_1d_ncw_fcw (linalg::Conv1DNcwFcwOp)
Performs 1-D convolution.
Layout:
- Input: NCW.
- Kernel: FCW.
Numeric casting is performed on the operands to the inner multiply, promoting them to the same data type as the accumulator/output.
Traits: AttrSizedOperandSegments, RecursiveMemoryEffects, SingleBlockImplicitTerminator<YieldOp>, SingleBlock
Interfaces: ConditionallySpeculatable, DestinationStyleOpInterface, IndexingMapOpInterface, LinalgConvolutionOpInterface, LinalgStructuredInterface, MemoryEffectOpInterface, ReifyRankedShapedTypeOpInterface
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
strides | ::mlir::DenseIntElementsAttr | 64-bit signless int elements attribute of shape [1] |
dilations | ::mlir::DenseIntElementsAttr | 64-bit signless int elements attribute of shape [1] |
Operands:
| Operand | Description |
|---|---|
inputs | variadic of any non-token type |
outputs | variadic of shaped of any non-token type values |
Results:
| Result | Description |
|---|---|
result_tensors | variadic of ranked tensor of any non-token type values |
linalg.conv_1d_nwc_wcf (linalg::Conv1DNwcWcfOp)
Performs 1-D convolution.
Numeric casting is performed on the operands to the inner multiply, promoting them to the same data type as the accumulator/output.
Traits: AttrSizedOperandSegments, RecursiveMemoryEffects, SingleBlockImplicitTerminator<YieldOp>, SingleBlock
Interfaces: ConditionallySpeculatable, DestinationStyleOpInterface, IndexingMapOpInterface, LinalgConvolutionOpInterface, LinalgStructuredInterface, MemoryEffectOpInterface, ReifyRankedShapedTypeOpInterface
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
strides | ::mlir::DenseIntElementsAttr | 64-bit signless int elements attribute of shape [1] |
dilations | ::mlir::DenseIntElementsAttr | 64-bit signless int elements attribute of shape [1] |
Operands:
| Operand | Description |
|---|---|
inputs | variadic of any non-token type |
outputs | variadic of shaped of any non-token type values |
Results:
| Result | Description |
|---|---|
result_tensors | variadic of ranked tensor of any non-token type values |
linalg.conv_2d (linalg::Conv2DOp)
Performs 2-D convolution with no channels.
Numeric casting is performed on the operands to the inner multiply, promoting them to the same data type as the accumulator/output.
Traits: AttrSizedOperandSegments, RecursiveMemoryEffects, SingleBlockImplicitTerminator<YieldOp>, SingleBlock
Interfaces: ConditionallySpeculatable, DestinationStyleOpInterface, IndexingMapOpInterface, LinalgConvolutionOpInterface, LinalgStructuredInterface, MemoryEffectOpInterface, ReifyRankedShapedTypeOpInterface
Operands:
| Operand | Description |
|---|---|
inputs | variadic of any non-token type |
outputs | variadic of shaped of any non-token type values |
Results:
| Result | Description |
|---|---|
result_tensors | variadic of ranked tensor of any non-token type values |
linalg.conv_2d_nchw_fchw (linalg::Conv2DNchwFchwOp)
Performs 2-D convolution.
Layout:
- Input: NCHW.
- Kernel: FCHW.
Numeric casting is performed on the operands to the inner multiply, promoting them to the same data type as the accumulator/output.
Traits: AttrSizedOperandSegments, RecursiveMemoryEffects, SingleBlockImplicitTerminator<YieldOp>, SingleBlock
Interfaces: ConditionallySpeculatable, DestinationStyleOpInterface, IndexingMapOpInterface, LinalgConvolutionOpInterface, LinalgStructuredInterface, MemoryEffectOpInterface, ReifyRankedShapedTypeOpInterface
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
strides | ::mlir::DenseIntElementsAttr | 64-bit signless int elements attribute of shape [2] |
dilations | ::mlir::DenseIntElementsAttr | 64-bit signless int elements attribute of shape [2] |
Operands:
| Operand | Description |
|---|---|
inputs | variadic of any non-token type |
outputs | variadic of shaped of any non-token type values |
Results:
| Result | Description |
|---|---|
result_tensors | variadic of ranked tensor of any non-token type values |
linalg.conv_2d_nchw_fchw_q (linalg::Conv2DNchwFchwQOp)
Performs 2-D convolution with zero point offsets.
Layout:
- Input: NCHW.
- Kernel: FCHW.
Numeric casting is performed on the operands to the inner multiply, promoting them to the same data type as the accumulator/output. This includes the zero point offsets common to quantized operations.
Traits: AttrSizedOperandSegments, RecursiveMemoryEffects, SingleBlockImplicitTerminator<YieldOp>, SingleBlock
Interfaces: ConditionallySpeculatable, DestinationStyleOpInterface, IndexingMapOpInterface, LinalgConvolutionOpInterface, LinalgStructuredInterface, MemoryEffectOpInterface, ReifyRankedShapedTypeOpInterface
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
strides | ::mlir::DenseIntElementsAttr | 64-bit signless int elements attribute of shape [2] |
dilations | ::mlir::DenseIntElementsAttr | 64-bit signless int elements attribute of shape [2] |
Operands:
| Operand | Description |
|---|---|
inputs | variadic of any non-token type |
outputs | variadic of shaped of any non-token type values |
Results:
| Result | Description |
|---|---|
result_tensors | variadic of ranked tensor of any non-token type values |
linalg.conv_2d_ngchw_fgchw (linalg::Conv2DNgchwFgchwOp)
Performs 2-D grouped convolution.
Layout:
- Input: NGCHW.
- Kernel: FGCHW.
Numeric casting is performed on the operands to the inner multiply, promoting them to the same data type as the accumulator/output.
Traits: AttrSizedOperandSegments, RecursiveMemoryEffects, SingleBlockImplicitTerminator<YieldOp>, SingleBlock
Interfaces: ConditionallySpeculatable, DestinationStyleOpInterface, IndexingMapOpInterface, LinalgConvolutionOpInterface, LinalgStructuredInterface, MemoryEffectOpInterface, ReifyRankedShapedTypeOpInterface
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
strides | ::mlir::DenseIntElementsAttr | 64-bit signless int elements attribute of shape [2] |
dilations | ::mlir::DenseIntElementsAttr | 64-bit signless int elements attribute of shape [2] |
Operands:
| Operand | Description |
|---|---|
inputs | variadic of any non-token type |
outputs | variadic of shaped of any non-token type values |
Results:
| Result | Description |
|---|---|
result_tensors | variadic of ranked tensor of any non-token type values |
linalg.conv_2d_ngchw_gfchw (linalg::Conv2DNgchwGfchwOp)
Performs 2-D grouped convolution.
Layout:
- Input: NGCHW.
- Kernel: GFCHW.
Numeric casting is performed on the operands to the inner multiply, promoting them to the same data type as the accumulator/output.
Traits: AttrSizedOperandSegments, RecursiveMemoryEffects, SingleBlockImplicitTerminator<YieldOp>, SingleBlock
Interfaces: ConditionallySpeculatable, DestinationStyleOpInterface, IndexingMapOpInterface, LinalgConvolutionOpInterface, LinalgStructuredInterface, MemoryEffectOpInterface, ReifyRankedShapedTypeOpInterface
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
strides | ::mlir::DenseIntElementsAttr | 64-bit signless int elements attribute of shape [2] |
dilations | ::mlir::DenseIntElementsAttr | 64-bit signless int elements attribute of shape [2] |
Operands:
| Operand | Description |
|---|---|
inputs | variadic of any non-token type |
outputs | variadic of shaped of any non-token type values |
Results:
| Result | Description |
|---|---|
result_tensors | variadic of ranked tensor of any non-token type values |
linalg.conv_2d_ngchw_gfchw_q (linalg::Conv2DNgchwGfchwQOp)
Performs 2-D grouped convolution with zero-point offsets.
Layout:
- Input: NGCHW.
- Kernel: GFCHW.
Numeric casting is performed on the operands to the inner multiply, promoting them to the same data type as the accumulator/output. This includes the zero point offsets common to quantized operations.
Traits: AttrSizedOperandSegments, RecursiveMemoryEffects, SingleBlockImplicitTerminator<YieldOp>, SingleBlock
Interfaces: ConditionallySpeculatable, DestinationStyleOpInterface, IndexingMapOpInterface, LinalgConvolutionOpInterface, LinalgStructuredInterface, MemoryEffectOpInterface, ReifyRankedShapedTypeOpInterface
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
strides | ::mlir::DenseIntElementsAttr | 64-bit signless int elements attribute of shape [2] |
dilations | ::mlir::DenseIntElementsAttr | 64-bit signless int elements attribute of shape [2] |
Operands:
| Operand | Description |
|---|---|
inputs | variadic of any non-token type |
outputs | variadic of shaped of any non-token type values |
Results:
| Result | Description |
|---|---|
result_tensors | variadic of ranked tensor of any non-token type values |
linalg.conv_2d_nhwc_fhwc (linalg::Conv2DNhwcFhwcOp)
Performs 2-D convolution.
Layout:
- Input: NHWC.
- Kernel: FHWC.
Numeric casting is performed on the operands to the inner multiply, promoting them to the same data type as the accumulator/output.
Traits: AttrSizedOperandSegments, RecursiveMemoryEffects, SingleBlockImplicitTerminator<YieldOp>, SingleBlock
Interfaces: ConditionallySpeculatable, DestinationStyleOpInterface, IndexingMapOpInterface, LinalgConvolutionOpInterface, LinalgStructuredInterface, MemoryEffectOpInterface, ReifyRankedShapedTypeOpInterface
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
strides | ::mlir::DenseIntElementsAttr | 64-bit signless int elements attribute of shape [2] |
dilations | ::mlir::DenseIntElementsAttr | 64-bit signless int elements attribute of shape [2] |
Operands:
| Operand | Description |
|---|---|
inputs | variadic of any non-token type |
outputs | variadic of shaped of any non-token type values |
Results:
| Result | Description |
|---|---|
result_tensors | variadic of ranked tensor of any non-token type values |
linalg.conv_2d_nhwc_fhwc_q (linalg::Conv2DNhwcFhwcQOp)
Performs 2-D convolution with zero point offsets.
Layout:
- Input: NHWC.
- Kernel: FHWC.
Numeric casting is performed on the operands to the inner multiply, promoting them to the same data type as the accumulator/output. This includes the zero point offsets common to quantized operations.
Traits: AttrSizedOperandSegments, RecursiveMemoryEffects, SingleBlockImplicitTerminator<YieldOp>, SingleBlock
Interfaces: ConditionallySpeculatable, DestinationStyleOpInterface, IndexingMapOpInterface, LinalgConvolutionOpInterface, LinalgStructuredInterface, MemoryEffectOpInterface, ReifyRankedShapedTypeOpInterface
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
strides | ::mlir::DenseIntElementsAttr | 64-bit signless int elements attribute of shape [2] |
dilations | ::mlir::DenseIntElementsAttr | 64-bit signless int elements attribute of shape [2] |
Operands:
| Operand | Description |
|---|---|
inputs | variadic of any non-token type |
outputs | variadic of shaped of any non-token type values |
Results:
| Result | Description |
|---|---|
result_tensors | variadic of ranked tensor of any non-token type values |
linalg.conv_2d_nhwc_hwcf (linalg::Conv2DNhwcHwcfOp)
Performs 2-D convolution.
Layout:
- Input: NHWC.
- Kernel: HWCF.
Numeric casting is performed on the operands to the inner multiply, promoting them to the same data type as the accumulator/output.
Traits: AttrSizedOperandSegments, RecursiveMemoryEffects, SingleBlockImplicitTerminator<YieldOp>, SingleBlock
Interfaces: ConditionallySpeculatable, DestinationStyleOpInterface, IndexingMapOpInterface, LinalgConvolutionOpInterface, LinalgStructuredInterface, MemoryEffectOpInterface, ReifyRankedShapedTypeOpInterface
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
strides | ::mlir::DenseIntElementsAttr | 64-bit signless int elements attribute of shape [2] |
dilations | ::mlir::DenseIntElementsAttr | 64-bit signless int elements attribute of shape [2] |
Operands:
| Operand | Description |
|---|---|
inputs | variadic of any non-token type |
outputs | variadic of shaped of any non-token type values |
Results:
| Result | Description |
|---|---|
result_tensors | variadic of ranked tensor of any non-token type values |
linalg.conv_2d_nhwc_hwcf_q (linalg::Conv2DNhwcHwcfQOp)
Performs 2-D convolution with zero point offsets.
Layout:
- Input: NHWC.
- Kernel: HWCF.
Numeric casting is performed on the operands to the inner multiply, promoting them to the same data type as the accumulator/output. This includes the zero point offsets common to quantized operations.
Traits: AttrSizedOperandSegments, RecursiveMemoryEffects, SingleBlockImplicitTerminator<YieldOp>, SingleBlock
Interfaces: ConditionallySpeculatable, DestinationStyleOpInterface, IndexingMapOpInterface, LinalgConvolutionOpInterface, LinalgStructuredInterface, MemoryEffectOpInterface, ReifyRankedShapedTypeOpInterface
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
strides | ::mlir::DenseIntElementsAttr | 64-bit signless int elements attribute of shape [2] |
dilations | ::mlir::DenseIntElementsAttr | 64-bit signless int elements attribute of shape [2] |
Operands:
| Operand | Description |
|---|---|
inputs | variadic of any non-token type |
outputs | variadic of shaped of any non-token type values |
Results:
| Result | Description |
|---|---|
result_tensors | variadic of ranked tensor of any non-token type values |
linalg.conv_2d_nhwgc_gfhwc (linalg::Conv2DNhwgcGfhwcOp)
Performs 2-D grouped convolution.
Layout:
- Input: NHWGC.
- Kernel: GFHWC.
Numeric casting is performed on the operands to the inner multiply, promoting them to the same data type as the accumulator/output.
Traits: AttrSizedOperandSegments, RecursiveMemoryEffects, SingleBlockImplicitTerminator<YieldOp>, SingleBlock
Interfaces: ConditionallySpeculatable, DestinationStyleOpInterface, IndexingMapOpInterface, LinalgConvolutionOpInterface, LinalgStructuredInterface, MemoryEffectOpInterface, ReifyRankedShapedTypeOpInterface
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
strides | ::mlir::DenseIntElementsAttr | 64-bit signless int elements attribute of shape [2] |
dilations | ::mlir::DenseIntElementsAttr | 64-bit signless int elements attribute of shape [2] |
Operands:
| Operand | Description |
|---|---|
inputs | variadic of any non-token type |
outputs | variadic of shaped of any non-token type values |
Results:
| Result | Description |
|---|---|
result_tensors | variadic of ranked tensor of any non-token type values |
linalg.conv_2d_nhwgc_gfhwc_q (linalg::Conv2DNhwgcGfhwcQOp)
Performs 2-D grouped convolution with zero point offsets.
Layout:
- Input: NHWGC.
- Kernel: GFHWC.
Numeric casting is performed on the operands to the inner multiply, promoting them to the same data type as the accumulator/output. This includes the zero point offsets common to quantized operations.
Traits: AttrSizedOperandSegments, RecursiveMemoryEffects, SingleBlockImplicitTerminator<YieldOp>, SingleBlock
Interfaces: ConditionallySpeculatable, DestinationStyleOpInterface, IndexingMapOpInterface, LinalgConvolutionOpInterface, LinalgStructuredInterface, MemoryEffectOpInterface, ReifyRankedShapedTypeOpInterface
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
strides | ::mlir::DenseIntElementsAttr | 64-bit signless int elements attribute of shape [2] |
dilations | ::mlir::DenseIntElementsAttr | 64-bit signless int elements attribute of shape [2] |
Operands:
| Operand | Description |
|---|---|
inputs | variadic of any non-token type |
outputs | variadic of shaped of any non-token type values |
Results:
| Result | Description |
|---|---|
result_tensors | variadic of ranked tensor of any non-token type values |
linalg.conv_3d (linalg::Conv3DOp)
Performs 3-D convolution with no channels.
Numeric casting is performed on the operands to the inner multiply, promoting them to the same data type as the accumulator/output.
Traits: AttrSizedOperandSegments, RecursiveMemoryEffects, SingleBlockImplicitTerminator<YieldOp>, SingleBlock
Interfaces: ConditionallySpeculatable, DestinationStyleOpInterface, IndexingMapOpInterface, LinalgConvolutionOpInterface, LinalgStructuredInterface, MemoryEffectOpInterface, ReifyRankedShapedTypeOpInterface
Operands:
| Operand | Description |
|---|---|
inputs | variadic of any non-token type |
outputs | variadic of shaped of any non-token type values |
Results:
| Result | Description |
|---|---|
result_tensors | variadic of ranked tensor of any non-token type values |
linalg.conv_3d_ncdhw_fcdhw (linalg::Conv3DNcdhwFcdhwOp)
Performs 3-D convolution.
Numeric casting is performed on the operands to the inner multiply, promoting them to the same data type as the accumulator/output.
Traits: AttrSizedOperandSegments, RecursiveMemoryEffects, SingleBlockImplicitTerminator<YieldOp>, SingleBlock
Interfaces: ConditionallySpeculatable, DestinationStyleOpInterface, IndexingMapOpInterface, LinalgConvolutionOpInterface, LinalgStructuredInterface, MemoryEffectOpInterface, ReifyRankedShapedTypeOpInterface
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
strides | ::mlir::DenseIntElementsAttr | 64-bit signless int elements attribute of shape [3] |
dilations | ::mlir::DenseIntElementsAttr | 64-bit signless int elements attribute of shape [3] |
Operands:
| Operand | Description |
|---|---|
inputs | variadic of any non-token type |
outputs | variadic of shaped of any non-token type values |
Results:
| Result | Description |
|---|---|
result_tensors | variadic of ranked tensor of any non-token type values |
linalg.conv_3d_ndhwc_dhwcf (linalg::Conv3DNdhwcDhwcfOp)
Performs 3-D convolution.
Numeric casting is performed on the operands to the inner multiply, promoting them to the same data type as the accumulator/output.
Traits: AttrSizedOperandSegments, RecursiveMemoryEffects, SingleBlockImplicitTerminator<YieldOp>, SingleBlock
Interfaces: ConditionallySpeculatable, DestinationStyleOpInterface, IndexingMapOpInterface, LinalgConvolutionOpInterface, LinalgStructuredInterface, MemoryEffectOpInterface, ReifyRankedShapedTypeOpInterface
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
strides | ::mlir::DenseIntElementsAttr | 64-bit signless int elements attribute of shape [3] |
dilations | ::mlir::DenseIntElementsAttr | 64-bit signless int elements attribute of shape [3] |
Operands:
| Operand | Description |
|---|---|
inputs | variadic of any non-token type |
outputs | variadic of shaped of any non-token type values |
Results:
| Result | Description |
|---|---|
result_tensors | variadic of ranked tensor of any non-token type values |
linalg.conv_3d_ndhwc_dhwcf_q (linalg::Conv3DNdhwcDhwcfQOp)
Performs 3-D convolution with zero point offsets.
Numeric casting is performed on the operands to the inner multiply, promoting them to the same data type as the accumulator/output. This includes the zero point offsets common to quantized operations.
Traits: AttrSizedOperandSegments, RecursiveMemoryEffects, SingleBlockImplicitTerminator<YieldOp>, SingleBlock
Interfaces: ConditionallySpeculatable, DestinationStyleOpInterface, IndexingMapOpInterface, LinalgConvolutionOpInterface, LinalgStructuredInterface, MemoryEffectOpInterface, ReifyRankedShapedTypeOpInterface
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
strides | ::mlir::DenseIntElementsAttr | 64-bit signless int elements attribute of shape [3] |
dilations | ::mlir::DenseIntElementsAttr | 64-bit signless int elements attribute of shape [3] |
Operands:
| Operand | Description |
|---|---|
inputs | variadic of any non-token type |
outputs | variadic of shaped of any non-token type values |
Results:
| Result | Description |
|---|---|
result_tensors | variadic of ranked tensor of any non-token type values |
linalg.copy (linalg::CopyOp)
Copies the tensor elementwise.
Numeric casting is performed on the input operand, promoting it to the same data type as the accumulator/output.
Traits: AttrSizedOperandSegments, RecursiveMemoryEffects, SingleBlockImplicitTerminator<YieldOp>, SingleBlock
Interfaces: ConditionallySpeculatable, DestinationStyleOpInterface, IndexingMapOpInterface, LinalgStructuredInterface, MemoryEffectOpInterface, ReifyRankedShapedTypeOpInterface
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
cast | ::mlir::linalg::TypeFnAttr | allowed 32-bit signless integer cases: 0, 1 |
Operands:
| Operand | Description |
|---|---|
inputs | variadic of any non-token type |
outputs | variadic of shaped of any non-token type values |
Results:
| Result | Description |
|---|---|
result_tensors | variadic of ranked tensor of any non-token type values |
linalg.depthwise_conv_1d_ncw_cw (linalg::DepthwiseConv1DNcwCwOp)
Performs depth-wise 1-D convolution.
Numeric casting is performed on the operands to the inner multiply, promoting them to the same data type as the accumulator/output. Multiplier is set to 1 which is a special case for most depthwise convolutions.
Traits: AttrSizedOperandSegments, RecursiveMemoryEffects, SingleBlockImplicitTerminator<YieldOp>, SingleBlock
Interfaces: ConditionallySpeculatable, DestinationStyleOpInterface, IndexingMapOpInterface, LinalgConvolutionOpInterface, LinalgStructuredInterface, MemoryEffectOpInterface, ReifyRankedShapedTypeOpInterface
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
strides | ::mlir::DenseIntElementsAttr | 64-bit signless int elements attribute of shape [1] |
dilations | ::mlir::DenseIntElementsAttr | 64-bit signless int elements attribute of shape [1] |
Operands:
| Operand | Description |
|---|---|
inputs | variadic of any non-token type |
outputs | variadic of shaped of any non-token type values |
Results:
| Result | Description |
|---|---|
result_tensors | variadic of ranked tensor of any non-token type values |
linalg.depthwise_conv_1d_nwc_wc (linalg::DepthwiseConv1DNwcWcOp)
Performs depth-wise 1-D convolution.
Numeric casting is performed on the operands to the inner multiply, promoting them to the same data type as the accumulator/output. Multiplier is set to 1 which is a special case for most depthwise convolutions.
Traits: AttrSizedOperandSegments, RecursiveMemoryEffects, SingleBlockImplicitTerminator<YieldOp>, SingleBlock
Interfaces: ConditionallySpeculatable, DestinationStyleOpInterface, IndexingMapOpInterface, LinalgConvolutionOpInterface, LinalgStructuredInterface, MemoryEffectOpInterface, ReifyRankedShapedTypeOpInterface
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
strides | ::mlir::DenseIntElementsAttr | 64-bit signless int elements attribute of shape [1] |
dilations | ::mlir::DenseIntElementsAttr | 64-bit signless int elements attribute of shape [1] |
Operands:
| Operand | Description |
|---|---|
inputs | variadic of any non-token type |
outputs | variadic of shaped of any non-token type values |
Results:
| Result | Description |
|---|---|
result_tensors | variadic of ranked tensor of any non-token type values |
linalg.depthwise_conv_1d_nwc_wcm (linalg::DepthwiseConv1DNwcWcmOp)
Performs depth-wise 1-D convolution.
Numeric casting is performed on the operands to the inner multiply, promoting them to the same data type as the accumulator/output.
Traits: AttrSizedOperandSegments, RecursiveMemoryEffects, SingleBlockImplicitTerminator<YieldOp>, SingleBlock
Interfaces: ConditionallySpeculatable, DestinationStyleOpInterface, IndexingMapOpInterface, LinalgConvolutionOpInterface, LinalgStructuredInterface, MemoryEffectOpInterface, ReifyRankedShapedTypeOpInterface
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
strides | ::mlir::DenseIntElementsAttr | 64-bit signless int elements attribute of shape [1] |
dilations | ::mlir::DenseIntElementsAttr | 64-bit signless int elements attribute of shape [1] |
Operands:
| Operand | Description |
|---|---|
inputs | variadic of any non-token type |
outputs | variadic of shaped of any non-token type values |
Results:
| Result | Description |
|---|---|
result_tensors | variadic of ranked tensor of any non-token type values |
linalg.depthwise_conv_2d_nchw_chw (linalg::DepthwiseConv2DNchwChwOp)
Performs depth-wise 2-D convolution.
Numeric casting is performed on the operands to the inner multiply, promoting them to the same data type as the accumulator/output. Multiplier is set to 1 which is a special case for most depthwise convolutions.
Traits: AttrSizedOperandSegments, RecursiveMemoryEffects, SingleBlockImplicitTerminator<YieldOp>, SingleBlock
Interfaces: ConditionallySpeculatable, DestinationStyleOpInterface, IndexingMapOpInterface, LinalgConvolutionOpInterface, LinalgStructuredInterface, MemoryEffectOpInterface, ReifyRankedShapedTypeOpInterface
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
strides | ::mlir::DenseIntElementsAttr | 64-bit signless int elements attribute of shape [2] |
dilations | ::mlir::DenseIntElementsAttr | 64-bit signless int elements attribute of shape [2] |
Operands:
| Operand | Description |
|---|---|
inputs | variadic of any non-token type |
outputs | variadic of shaped of any non-token type values |
Results:
| Result | Description |
|---|---|
result_tensors | variadic of ranked tensor of any non-token type values |
linalg.depthwise_conv_2d_nhwc_hwc (linalg::DepthwiseConv2DNhwcHwcOp)
Performs depth-wise 2-D convolution.
Numeric casting is performed on the operands to the inner multiply, promoting them to the same data type as the accumulator/output. Multiplier is set to 1 which is a special case for most depthwise convolutions.
Traits: AttrSizedOperandSegments, RecursiveMemoryEffects, SingleBlockImplicitTerminator<YieldOp>, SingleBlock
Interfaces: ConditionallySpeculatable, DestinationStyleOpInterface, IndexingMapOpInterface, LinalgConvolutionOpInterface, LinalgStructuredInterface, MemoryEffectOpInterface, ReifyRankedShapedTypeOpInterface
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
strides | ::mlir::DenseIntElementsAttr | 64-bit signless int elements attribute of shape [2] |
dilations | ::mlir::DenseIntElementsAttr | 64-bit signless int elements attribute of shape [2] |
Operands:
| Operand | Description |
|---|---|
inputs | variadic of any non-token type |
outputs | variadic of shaped of any non-token type values |
Results:
| Result | Description |
|---|---|
result_tensors | variadic of ranked tensor of any non-token type values |
linalg.depthwise_conv_2d_nhwc_hwc_q (linalg::DepthwiseConv2DNhwcHwcQOp)
Performs depth-wise 2-D convolution.
Numeric casting is performed on the operands to the inner multiply, promoting them to the same data type as the accumulator/output.
Traits: AttrSizedOperandSegments, RecursiveMemoryEffects, SingleBlockImplicitTerminator<YieldOp>, SingleBlock
Interfaces: ConditionallySpeculatable, DestinationStyleOpInterface, IndexingMapOpInterface, LinalgConvolutionOpInterface, LinalgStructuredInterface, MemoryEffectOpInterface, ReifyRankedShapedTypeOpInterface
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
strides | ::mlir::DenseIntElementsAttr | 64-bit signless int elements attribute of shape [2] |
dilations | ::mlir::DenseIntElementsAttr | 64-bit signless int elements attribute of shape [2] |
Operands:
| Operand | Description |
|---|---|
inputs | variadic of any non-token type |
outputs | variadic of shaped of any non-token type values |
Results:
| Result | Description |
|---|---|
result_tensors | variadic of ranked tensor of any non-token type values |
linalg.depthwise_conv_2d_nhwc_hwcm (linalg::DepthwiseConv2DNhwcHwcmOp)
Performs depth-wise 2-D convolution.
Numeric casting is performed on the operands to the inner multiply, promoting them to the same data type as the accumulator/output.
Traits: AttrSizedOperandSegments, RecursiveMemoryEffects, SingleBlockImplicitTerminator<YieldOp>, SingleBlock
Interfaces: ConditionallySpeculatable, DestinationStyleOpInterface, IndexingMapOpInterface, LinalgConvolutionOpInterface, LinalgStructuredInterface, MemoryEffectOpInterface, ReifyRankedShapedTypeOpInterface
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
strides | ::mlir::DenseIntElementsAttr | 64-bit signless int elements attribute of shape [2] |
dilations | ::mlir::DenseIntElementsAttr | 64-bit signless int elements attribute of shape [2] |
Operands:
| Operand | Description |
|---|---|
inputs | variadic of any non-token type |
outputs | variadic of shaped of any non-token type values |
Results:
| Result | Description |
|---|---|
result_tensors | variadic of ranked tensor of any non-token type values |
linalg.depthwise_conv_2d_nhwc_hwcm_q (linalg::DepthwiseConv2DNhwcHwcmQOp)
Performs depth-wise 2-D convolution.
Numeric casting is performed on the operands to the inner multiply, promoting them to the same data type as the accumulator/output.
Traits: AttrSizedOperandSegments, RecursiveMemoryEffects, SingleBlockImplicitTerminator<YieldOp>, SingleBlock
Interfaces: ConditionallySpeculatable, DestinationStyleOpInterface, IndexingMapOpInterface, LinalgConvolutionOpInterface, LinalgStructuredInterface, MemoryEffectOpInterface, ReifyRankedShapedTypeOpInterface
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
strides | ::mlir::DenseIntElementsAttr | 64-bit signless int elements attribute of shape [2] |
dilations | ::mlir::DenseIntElementsAttr | 64-bit signless int elements attribute of shape [2] |
Operands:
| Operand | Description |
|---|---|
inputs | variadic of any non-token type |
outputs | variadic of shaped of any non-token type values |
Results:
| Result | Description |
|---|---|
result_tensors | variadic of ranked tensor of any non-token type values |
linalg.depthwise_conv_3d_ncdhw_cdhw (linalg::DepthwiseConv3DNcdhwCdhwOp)
Performs depth-wise 3-D convolution.
Numeric casting is performed on the operands to the inner multiply, promoting them to the same data type as the accumulator/output. Multiplier is set to 1 which is a special case for most depthwise convolutions.
Traits: AttrSizedOperandSegments, RecursiveMemoryEffects, SingleBlockImplicitTerminator<YieldOp>, SingleBlock
Interfaces: ConditionallySpeculatable, DestinationStyleOpInterface, IndexingMapOpInterface, LinalgConvolutionOpInterface, LinalgStructuredInterface, MemoryEffectOpInterface, ReifyRankedShapedTypeOpInterface
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
strides | ::mlir::DenseIntElementsAttr | 64-bit signless int elements attribute of shape [3] |
dilations | ::mlir::DenseIntElementsAttr | 64-bit signless int elements attribute of shape [3] |
Operands:
| Operand | Description |
|---|---|
inputs | variadic of any non-token type |
outputs | variadic of shaped of any non-token type values |
Results:
| Result | Description |
|---|---|
result_tensors | variadic of ranked tensor of any non-token type values |
linalg.depthwise_conv_3d_ndhwc_dhwc (linalg::DepthwiseConv3DNdhwcDhwcOp)
Performs depth-wise 3-D convolution.
Numeric casting is performed on the operands to the inner multiply, promoting them to the same data type as the accumulator/output. Multiplier is set to 1 which is a special case for most depthwise convolutions.
Traits: AttrSizedOperandSegments, RecursiveMemoryEffects, SingleBlockImplicitTerminator<YieldOp>, SingleBlock
Interfaces: ConditionallySpeculatable, DestinationStyleOpInterface, IndexingMapOpInterface, LinalgConvolutionOpInterface, LinalgStructuredInterface, MemoryEffectOpInterface, ReifyRankedShapedTypeOpInterface
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
strides | ::mlir::DenseIntElementsAttr | 64-bit signless int elements attribute of shape [3] |
dilations | ::mlir::DenseIntElementsAttr | 64-bit signless int elements attribute of shape [3] |
Operands:
| Operand | Description |
|---|---|
inputs | variadic of any non-token type |
outputs | variadic of shaped of any non-token type values |
Results:
| Result | Description |
|---|---|
result_tensors | variadic of ranked tensor of any non-token type values |
linalg.depthwise_conv_3d_ndhwc_dhwcm (linalg::DepthwiseConv3DNdhwcDhwcmOp)
Performs depth-wise 3-D convolution.
Numeric casting is performed on the operands to the inner multiply, promoting them to the same data type as the accumulator/output.
Traits: AttrSizedOperandSegments, RecursiveMemoryEffects, SingleBlockImplicitTerminator<YieldOp>, SingleBlock
Interfaces: ConditionallySpeculatable, DestinationStyleOpInterface, IndexingMapOpInterface, LinalgConvolutionOpInterface, LinalgStructuredInterface, MemoryEffectOpInterface, ReifyRankedShapedTypeOpInterface
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
strides | ::mlir::DenseIntElementsAttr | 64-bit signless int elements attribute of shape [3] |
dilations | ::mlir::DenseIntElementsAttr | 64-bit signless int elements attribute of shape [3] |
Operands:
| Operand | Description |
|---|---|
inputs | variadic of any non-token type |
outputs | variadic of shaped of any non-token type values |
Results:
| Result | Description |
|---|---|
result_tensors | variadic of ranked tensor of any non-token type values |
linalg.div (linalg::DivOp)
Divides the first tensor by the second tensor, elementwise.
The shapes and element types must be identical. The appropriate casts, broadcasts and reductions should be done previously to calling this op.
This means reduction/broadcast/element cast semantics is explicit. Further
passes can take that into account when lowering this code. For example,
a linalg.broadcast + linalg.div sequence can be lowered to a
linalg.generic with different affine maps for the two operands.
Traits: AttrSizedOperandSegments, RecursiveMemoryEffects, SingleBlockImplicitTerminator<YieldOp>, SingleBlock
Interfaces: ConditionallySpeculatable, DestinationStyleOpInterface, IndexingMapOpInterface, LinalgStructuredInterface, MemoryEffectOpInterface, ReifyRankedShapedTypeOpInterface
Operands:
| Operand | Description |
|---|---|
inputs | variadic of any non-token type |
outputs | variadic of shaped of any non-token type values |
Results:
| Result | Description |
|---|---|
result_tensors | variadic of ranked tensor of any non-token type values |
linalg.div_unsigned (linalg::DivUnsignedOp)
Divides the first tensor by the second tensor, elementwise. For integer types, performs an unsigned division.
The shapes and element types must be identical. The appropriate casts, broadcasts and reductions should be done previously to calling this op.
This means reduction/broadcast/element cast semantics is explicit. Further
passes can take that into account when lowering this code. For example,
a linalg.broadcast + linalg.div sequence can be lowered to a
linalg.generic with different affine maps for the two operands.
Traits: AttrSizedOperandSegments, RecursiveMemoryEffects, SingleBlockImplicitTerminator<YieldOp>, SingleBlock
Interfaces: ConditionallySpeculatable, DestinationStyleOpInterface, IndexingMapOpInterface, LinalgStructuredInterface, MemoryEffectOpInterface, ReifyRankedShapedTypeOpInterface
Operands:
| Operand | Description |
|---|---|
inputs | variadic of any non-token type |
outputs | variadic of shaped of any non-token type values |
Results:
| Result | Description |
|---|---|
result_tensors | variadic of ranked tensor of any non-token type values |
linalg.dot (linalg::DotOp)
Performs a dot product of two vectors to a scalar result.
Numeric casting is performed on the operands to the inner multiply, promoting them to the same data type as the accumulator/output.
Traits: AttrSizedOperandSegments, RecursiveMemoryEffects, SingleBlockImplicitTerminator<YieldOp>, SingleBlock
Interfaces: ConditionallySpeculatable, DestinationStyleOpInterface, IndexingMapOpInterface, LinalgContractionOpInterface, LinalgStructuredInterface, MemoryEffectOpInterface, ReifyRankedShapedTypeOpInterface
Operands:
| Operand | Description |
|---|---|
inputs | variadic of any non-token type |
outputs | variadic of shaped of any non-token type values |
Results:
| Result | Description |
|---|---|
result_tensors | variadic of ranked tensor of any non-token type values |
linalg.elementwise (linalg::ElementwiseOp)
Performs element-wise operation
The attribute kind describes arithmetic operation to perform. The
operation kind can be unary (e.g. max), binary (e.g. add) or ternary
(e.g. select).
By default, all indexing maps are identities. In the case of default indexing map, all input and output shapes must match. The number of dims in each of the identity maps is equal to the rank of the output type.
Affine-maps for operands and result are required to be provided by the user when a transpose and/or broadcast is needed on any operand. When a map is not provided, default identity maps are inferred for each operand.
Iterator-types are always all parallel.
Iterator-types are needed for constructing the underlying structured op.
The number of dims of the iterator-types are inferred from the rank of the result type.
Example:
Defining a unary linalg.elementwise with default indexing-map:
%exp = linalg.elementwise
kind=#linalg.elementwise_kind<exp>
ins(%x : tensor<4x16x8xf32>)
outs(%y: tensor<4x16x8xf32>) -> tensor<4x16x8xf32>
Defining a binary linalg.elementwise with user-defined indexing-map:
%add = linalg.elementwise
kind=#linalg.elementwise_kind<add>
indexing_maps = [#transpose, #broadcast, #identity]
ins(%exp, %arg1 : tensor<4x16x8xf32>, tensor<4x16xf32>)
outs(%arg2: tensor<4x8x16xf32>) -> tensor<4x8x16xf32>
Traits: AttrSizedOperandSegments, RecursiveMemoryEffects, SingleBlockImplicitTerminator<YieldOp>, SingleBlock
Interfaces: ConditionallySpeculatable, DestinationStyleOpInterface, IndexingMapOpInterface, LinalgStructuredInterface, MemoryEffectOpInterface, ReifyRankedShapedTypeOpInterface
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
kind | ::mlir::linalg::ElementwiseKindAttr | allowed 32-bit signless integer cases: 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35 |
indexing_maps | ::mlir::ArrayAttr | AffineMap array attribute |
Operands:
| Operand | Description |
|---|---|
inputs | variadic of any non-token type |
outputs | variadic of shaped of any non-token type values |
Results:
| Result | Description |
|---|---|
result_tensors | variadic of ranked tensor of any non-token type values |
linalg.erf (linalg::ErfOp)
Applies erf(x) elementwise.
No numeric casting is performed on the input operand.
Traits: AttrSizedOperandSegments, RecursiveMemoryEffects, SingleBlockImplicitTerminator<YieldOp>, SingleBlock
Interfaces: ConditionallySpeculatable, DestinationStyleOpInterface, IndexingMapOpInterface, LinalgStructuredInterface, MemoryEffectOpInterface, ReifyRankedShapedTypeOpInterface
Operands:
| Operand | Description |
|---|---|
inputs | variadic of any non-token type |
outputs | variadic of shaped of any non-token type values |
Results:
| Result | Description |
|---|---|
result_tensors | variadic of ranked tensor of any non-token type values |
linalg.exp (linalg::ExpOp)
Applies exp(x) elementwise.
No numeric casting is performed on the input operand.
Traits: AttrSizedOperandSegments, RecursiveMemoryEffects, SingleBlockImplicitTerminator<YieldOp>, SingleBlock
Interfaces: ConditionallySpeculatable, DestinationStyleOpInterface, IndexingMapOpInterface, LinalgStructuredInterface, MemoryEffectOpInterface, ReifyRankedShapedTypeOpInterface
Operands:
| Operand | Description |
|---|---|
inputs | variadic of any non-token type |
outputs | variadic of shaped of any non-token type values |
Results:
| Result | Description |
|---|---|
result_tensors | variadic of ranked tensor of any non-token type values |
linalg.fill (linalg::FillOp)
Fills the output tensor with the given value.
Works for arbitrary ranked output tensors since the operation performs scalar accesses only and is thus rank polymorphic. The value operand type must match the element type of the output.
Traits: AttrSizedOperandSegments, RecursiveMemoryEffects, SingleBlockImplicitTerminator<YieldOp>, SingleBlock
Interfaces: ConditionallySpeculatable, DestinationStyleOpInterface, IndexingMapOpInterface, LinalgFillOpInterface, LinalgStructuredInterface, MemoryEffectOpInterface, ReifyRankedShapedTypeOpInterface
Operands:
| Operand | Description |
|---|---|
inputs | variadic of any non-token type |
outputs | variadic of shaped of any non-token type values |
Results:
| Result | Description |
|---|---|
result_tensors | variadic of ranked tensor of any non-token type values |
linalg.fill_rng_2d (linalg::FillRng2DOp)
Fills the output tensor with pseudo random numbers.
The operation generations pseudo random numbers using a linear congruential generator. It provides no guarantees regarding the distribution of the generated random numbers. Instead of generating the random numbers sequentially, it instantiates one random number generator per data element and runs them in parallel. The seed operand and the indices of the data element seed the random number generation. The min and max operands limit the range of the generated random numbers.
Traits: AttrSizedOperandSegments, RecursiveMemoryEffects, SingleBlockImplicitTerminator<YieldOp>, SingleBlock
Interfaces: ConditionallySpeculatable, DestinationStyleOpInterface, IndexingMapOpInterface, LinalgStructuredInterface, MemoryEffectOpInterface, ReifyRankedShapedTypeOpInterface
Operands:
| Operand | Description |
|---|---|
inputs | variadic of any non-token type |
outputs | variadic of shaped of any non-token type values |
Results:
| Result | Description |
|---|---|
result_tensors | variadic of ranked tensor of any non-token type values |
linalg.floor (linalg::FloorOp)
Applies floor(x) elementwise.
No numeric casting is performed on the input operand.
Traits: AttrSizedOperandSegments, RecursiveMemoryEffects, SingleBlockImplicitTerminator<YieldOp>, SingleBlock
Interfaces: ConditionallySpeculatable, DestinationStyleOpInterface, IndexingMapOpInterface, LinalgStructuredInterface, MemoryEffectOpInterface, ReifyRankedShapedTypeOpInterface
Operands:
| Operand | Description |
|---|---|
inputs | variadic of any non-token type |
outputs | variadic of shaped of any non-token type values |
Results:
| Result | Description |
|---|---|
result_tensors | variadic of ranked tensor of any non-token type values |
linalg.generic (linalg::GenericOp)
Generic Linalg op form where the key properties of the computation are
specified as attributes. In pretty form, a linalg.generic op is written
as:
linalg.generic #trait_attribute
ins(%A, %B : memref<?x?xf32, stride_specification>,
memref<?x?xf32, stride_specification>)
outs(%C : memref<?x?xf32, stride_specification>)
attrs = {other-optional-attributes}
{region}
Where #trait_attributes is an alias of a dictionary attribute containing:
- doc [optional]: a documentation string
- indexing_maps: a list of AffineMapAttr, one AffineMapAttr per each input and output view. Such AffineMapAttr specifies the mapping between the loops and the indexing within each view.
- library_call [optional]: a StringAttr containing the name of an external library function that the linalg.generic operation maps to. The external library is assumed to be dynamically linked and no strong compile-time guarantees are provided. In the absence of such a library call, linalg.generic will always lower to loops.
- iterator_types: an ArrayAttr specifying the type of the enclosing loops. Each element of the list represents and iterator of one of the following types: parallel, reduction, window
Example: Defining a #matmul_trait attribute in MLIR can be done as follows:
#matmul_accesses = [
(m, n, k) -> (m, k),
(m, n, k) -> (k, n),
(m, n, k) -> (m, n)
]
#matmul_trait = {
doc = "C(m, n) += A(m, k) * B(k, n)",
indexing_maps = #matmul_accesses,
library_call = "linalg_matmul",
iterator_types = ["parallel", "parallel", "reduction"]
}
And can be reused in multiple places as:
linalg.generic #matmul_trait
ins(%A, %B : memref<?x?xf32, stride_specification>,
memref<?x?xf32, stride_specification>)
outs(%C : memref<?x?xf32, stride_specification>)
{other-optional-attributes} {
^bb0(%a: f32, %b: f32, %c: f32) :
%d = arith.mulf %a, %b: f32
%e = arith.addf %c, %d: f32
linalg.yield %e : f32
}
This may lower to either:
call @linalg_matmul(%A, %B, %C) :
(memref<?x?xf32, stride_specification>,
memref<?x?xf32, stride_specification>,
memref<?x?xf32, stride_specification>)
-> ()
or IR resembling:
scf.for %m = %c0 to %M step %c1 {
scf.for %n = %c0 to %N step %c1 {
scf.for %k = %c0 to %K step %c1 {
%a = load %A[%m, %k] : memref<?x?xf32, stride_specification>
%b = load %B[%k, %n] : memref<?x?xf32, stride_specification>
%c = load %C[%m, %n] : memref<?x?xf32, stride_specification>
%d = arith.mulf %a, %b: f32
%e = arith.addf %c, %d: f32
store %e, %C[%m, %n] : memref<?x?x?xf32, stride_specification>
}
}
}
Traits: AttrSizedOperandSegments, RecursiveMemoryEffects, SingleBlockImplicitTerminator<YieldOp>, SingleBlock
Interfaces: ConditionallySpeculatable, DestinationStyleOpInterface, IndexingMapOpInterface, LinalgStructuredInterface, MemoryEffectOpInterface, OpAsmOpInterface, ReifyRankedShapedTypeOpInterface
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
indexing_maps | ::mlir::ArrayAttr | AffineMap array attribute |
iterator_types | ::mlir::ArrayAttr | Iterator type should be an enum. |
doc | ::mlir::StringAttr | string attribute |
library_call | ::mlir::StringAttr | string attribute |
Operands:
| Operand | Description |
|---|---|
inputs | variadic of any non-token type |
outputs | variadic of shaped of any non-token type values |
Results:
| Result | Description |
|---|---|
result_tensors | variadic of ranked tensor of any non-token type values |
linalg.index (linalg::IndexOp)
Linalg index operation
Syntax:
operation ::= `linalg.index` $dim attr-dict `:` type($result)
The linalg.index operation returns the iteration index of the immediately
enclosing linalg structured operation for the iteration dimension dim. The
dim attribute specifies the position of the accessed dimension in the
indexing map domain.
Example:
#map = affine_map<(i, j) -> (i, j)>
linalg.generic {indexing_maps = [#map, #map],
iterator_types = ["parallel", "parallel"]}
outs(%I, %J : memref<?x?xindex>, memref<?x?xindex>) {
^bb0(%arg0 : index, %arg1 : index):
// Access the outer iteration dimension i
%i = linalg.index 0 : index
// Access the inner iteration dimension j
%j = linalg.index 1 : index
linalg.yield %i, %j : index, index
}
This may lower to IR resembling:
%0 = dim %I, %c0 : memref<?x?xindex>
%1 = dim %I, %c1 : memref<?x?xindex>
scf.for %i = %c0 to %0 step %c1 {
scf.for %j = %c0 to %1 step %c1 {
store %i, %I[%i, %j] : memref<?x?xindex>
store %j, %J[%i, %j] : memref<?x?xindex>
}
}
Traits: AlwaysSpeculatableImplTrait
Interfaces: ConditionallySpeculatable, InferTypeOpInterface, NoMemoryEffect (MemoryEffectOpInterface)
Effects: MemoryEffects::Effect{}
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
dim | ::mlir::IntegerAttr | 64-bit signless integer attribute whose minimum value is 0 |
Results:
| Result | Description |
|---|---|
result | index |
linalg.log (linalg::LogOp)
Applies log(x) elementwise.
No numeric casting is performed on the input operand.
Traits: AttrSizedOperandSegments, RecursiveMemoryEffects, SingleBlockImplicitTerminator<YieldOp>, SingleBlock
Interfaces: ConditionallySpeculatable, DestinationStyleOpInterface, IndexingMapOpInterface, LinalgStructuredInterface, MemoryEffectOpInterface, ReifyRankedShapedTypeOpInterface
Operands:
| Operand | Description |
|---|---|
inputs | variadic of any non-token type |
outputs | variadic of shaped of any non-token type values |
Results:
| Result | Description |
|---|---|
result_tensors | variadic of ranked tensor of any non-token type values |
linalg.map (linalg::MapOp)
Elementwise operations
Models elementwise operations on tensors in terms of arithmetic operations on the corresponding elements.
Example:
%add = linalg.map
ins(%lhs, %rhs : tensor<64xf32>, tensor<64xf32>)
outs(%init: tensor<64xf32>)
(%lhs_elem: f32, %rhs_elem: f32) {
%0 = arith.addf %lhs_elem, %rhs_elem: f32
linalg.yield %0: f32
}
Shortened print form is available for simple maps where the body contains exactly two operations (the payload operation and a yield), the payload operation has the same number of operands as block arguments with operands matching block arguments in order, and the yield operand is the result of the payload operation.
The example above will be printed using the shortened form as:
%add = linalg.map { arith.addf }
ins(%lhs, %rhs : tensor<64xf32>, tensor<64xf32>)
outs(%init: tensor<64xf32>)
Traits: RecursiveMemoryEffects, SingleBlockImplicitTerminator<YieldOp>, SingleBlock
Interfaces: ConditionallySpeculatable, DestinationStyleOpInterface, IndexingMapOpInterface, LinalgStructuredInterface, MemoryEffectOpInterface, OpAsmOpInterface, ReifyRankedShapedTypeOpInterface
Operands:
| Operand | Description |
|---|---|
inputs | variadic of memref of any non-token type values or ranked tensor of any non-token type values |
init | memref of any non-token type values or ranked tensor of any non-token type values |
Results:
| Result | Description |
|---|---|
result | variadic of tensor of any non-token type values |
linalg.matmul (linalg::MatmulOp)
Performs a matrix multiplication of two 2D inputs without broadcast or transpose.
Numeric casting is performed on the operands to the inner multiply, promoting them to the same data type as the accumulator/output.
Broadcast and Transpose semantics can be appiled by specifying the explicit attribute ‘indexing_maps’ as shown below.This is a list attribute, so the list must include all the maps if specified.
Example Transpose:
linalg.matmul
indexing_maps = [affine_map<(m, n, k) -> (k, m)>, // transpose
affine_map<(m, n, k) -> (k, n)>,
affine_map<(m, n, k) -> (m, n)>]
ins(%arg0, %arg1 : memref<5x3xf32>,memref<5x7xf32>)
outs(%arg2: memref<3x7xf32>)
Example Broadcast:
linalg.matmul
indexing_maps = [affine_map<(m, n, k) -> (k)>, // broadcast
affine_map<(m, n, k) -> (k, n)>,
affine_map<(m, n, k) -> (m, n)>]
ins(%arg0, %arg1 : memref<3xf32>, memref<5x7xf32>)
outs(%arg2: memref<3x7xf32>)
Example Broadcast and transpose:
linalg.matmul
indexing_maps = [affine_map<(m, n, k) -> (k, m)>, // transpose
affine_map<(m, n, k) -> (k)>, // broadcast
affine_map<(m, n, k) -> (m, n)>]
ins(%arg0, %arg1 : memref<5x3xf32>, memref<7xf32>)
outs(%arg2: memref<3x7xf32>)
Traits: AttrSizedOperandSegments, RecursiveMemoryEffects, SingleBlockImplicitTerminator<YieldOp>, SingleBlock
Interfaces: ConditionallySpeculatable, DestinationStyleOpInterface, IndexingMapOpInterface, LinalgContractionOpInterface, LinalgStructuredInterface, MemoryEffectOpInterface, ReifyRankedShapedTypeOpInterface
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
indexing_maps | ::mlir::ArrayAttr | AffineMap array attribute |
cast | ::mlir::linalg::TypeFnAttr | allowed 32-bit signless integer cases: 0, 1 |
Operands:
| Operand | Description |
|---|---|
inputs | variadic of any non-token type |
outputs | variadic of shaped of any non-token type values |
Results:
| Result | Description |
|---|---|
result_tensors | variadic of ranked tensor of any non-token type values |
linalg.matvec (linalg::MatvecOp)
Performs a matrix-vector multiplication.
Numeric casting is performed on the operands to the inner multiply, promoting them to the same data type as the accumulator/output.
Traits: AttrSizedOperandSegments, RecursiveMemoryEffects, SingleBlockImplicitTerminator<YieldOp>, SingleBlock
Interfaces: ConditionallySpeculatable, DestinationStyleOpInterface, IndexingMapOpInterface, LinalgContractionOpInterface, LinalgStructuredInterface, MemoryEffectOpInterface, ReifyRankedShapedTypeOpInterface
Operands:
| Operand | Description |
|---|---|
inputs | variadic of any non-token type |
outputs | variadic of shaped of any non-token type values |
Results:
| Result | Description |
|---|---|
result_tensors | variadic of ranked tensor of any non-token type values |
linalg.max (linalg::MaxOp)
Takes the max (signed) between two inputs, elementwise.
The shapes and element types must be identical. The appropriate casts, broadcasts and reductions should be done previously to calling this op.
This means reduction/broadcast/element cast semantics is explicit. Further
passes can take that into account when lowering this code. For example,
a linalg.broadcast + linalg.max sequence can be lowered to a
linalg.generic with different affine maps for the two operands.
Traits: AttrSizedOperandSegments, RecursiveMemoryEffects, SingleBlockImplicitTerminator<YieldOp>, SingleBlock
Interfaces: ConditionallySpeculatable, DestinationStyleOpInterface, IndexingMapOpInterface, LinalgStructuredInterface, MemoryEffectOpInterface, ReifyRankedShapedTypeOpInterface
Operands:
| Operand | Description |
|---|---|
inputs | variadic of any non-token type |
outputs | variadic of shaped of any non-token type values |
Results:
| Result | Description |
|---|---|
result_tensors | variadic of ranked tensor of any non-token type values |
linalg.min (linalg::MinOp)
Takes the min (signed) between two inputs, elementwise.
The shapes and element types must be identical. The appropriate casts, broadcasts and reductions should be done previously to calling this op.
This means reduction/broadcast/element cast semantics is explicit. Further
passes can take that into account when lowering this code. For example,
a linalg.broadcast + linalg.min sequence can be lowered to a
linalg.generic with different affine maps for the two operands.
Traits: AttrSizedOperandSegments, RecursiveMemoryEffects, SingleBlockImplicitTerminator<YieldOp>, SingleBlock
Interfaces: ConditionallySpeculatable, DestinationStyleOpInterface, IndexingMapOpInterface, LinalgStructuredInterface, MemoryEffectOpInterface, ReifyRankedShapedTypeOpInterface
Operands:
| Operand | Description |
|---|---|
inputs | variadic of any non-token type |
outputs | variadic of shaped of any non-token type values |
Results:
| Result | Description |
|---|---|
result_tensors | variadic of ranked tensor of any non-token type values |
linalg.mmt4d (linalg::Mmt4DOp)
Performs a matrix-matrix-transpose multiplication of two 4D inputs.
Differences from linalg.matmul:
- The right hand side is transposed, whence the ’t’ in ‘mmt’.
- The input and output tensors have a 4D shape instead of a 2D shape. They are interpreted as 2D matrices with one level of 2D tile subdivision, whence the 2+2=4 dimensions. The inner tile dimensions are identified with ‘0’ suffixes below, for instance the LHS matrix shape (M, K, M0, K0) reads as: MxK tiles, each of shape M0xK0.
Traits: AttrSizedOperandSegments, RecursiveMemoryEffects, SingleBlockImplicitTerminator<YieldOp>, SingleBlock
Interfaces: ConditionallySpeculatable, DestinationStyleOpInterface, IndexingMapOpInterface, LinalgContractionOpInterface, LinalgStructuredInterface, MemoryEffectOpInterface, ReifyRankedShapedTypeOpInterface
Operands:
| Operand | Description |
|---|---|
inputs | variadic of any non-token type |
outputs | variadic of shaped of any non-token type values |
Results:
| Result | Description |
|---|---|
result_tensors | variadic of ranked tensor of any non-token type values |
linalg.mul (linalg::MulOp)
Multiplies two tensors elementwise.
The shapes and element types must be identical. The appropriate casts, broadcasts and reductions should be done previously to calling this op.
This means reduction/broadcast/element cast semantics is explicit. Further
passes can take that into account when lowering this code. For example,
a linalg.broadcast + linalg.mul sequence can be lowered to a
linalg.generic with different affine maps for the two operands.
Traits: AttrSizedOperandSegments, RecursiveMemoryEffects, SingleBlockImplicitTerminator<YieldOp>, SingleBlock
Interfaces: ConditionallySpeculatable, DestinationStyleOpInterface, IndexingMapOpInterface, LinalgStructuredInterface, MemoryEffectOpInterface, ReifyRankedShapedTypeOpInterface
Operands:
| Operand | Description |
|---|---|
inputs | variadic of any non-token type |
outputs | variadic of shaped of any non-token type values |
Results:
| Result | Description |
|---|---|
result_tensors | variadic of ranked tensor of any non-token type values |
linalg.negf (linalg::NegFOp)
Applies negf(x) elementwise.
No numeric casting is performed on the input operand.
Traits: AttrSizedOperandSegments, RecursiveMemoryEffects, SingleBlockImplicitTerminator<YieldOp>, SingleBlock
Interfaces: ConditionallySpeculatable, DestinationStyleOpInterface, IndexingMapOpInterface, LinalgStructuredInterface, MemoryEffectOpInterface, ReifyRankedShapedTypeOpInterface
Operands:
| Operand | Description |
|---|---|
inputs | variadic of any non-token type |
outputs | variadic of shaped of any non-token type values |
Results:
| Result | Description |
|---|---|
result_tensors | variadic of ranked tensor of any non-token type values |
linalg.pack (linalg::PackOp)
Linalg.pack operation
The “pack” operation converts a source tensor of rank n into a result
tensor of rank n + k with a tiled and packed layout (maybe with padding)
and optionally transposes the tiled source tensor dimensions.
inner_tiles (mandatory) specifies k tile sizes. These tile sizes
correspond to the least significant (“inner”) result tensor dimension sizes,
in the same order. Tile sizes can be static or dynamic.
inner_dims_pos (mandatory) specifies k source tensor dimensions that are
being tiled, where 0 <= k <= n.
inner_dims_pos[i]specifies the source tensor dimension tiled byinner_tiles[i]where0 <= i < k. All the values ininner_dims_posare within [0, n).- The tiled dimensions (of size
inner_tiles) are added to the end of the result tensor in the order in which they appear, i.e.shape(result)[rank(source) + i] = inner_tiles[i]for0 <= i < k. - The following relationship for the tiled dimensions holds:
shape(result)[inner_dims_pos[i]] = shape(source)[inner_dims_pos[i]] / inner_tiles[i], where (⌈/⌉ indicates CeilDiv).
Example: If inner_tiles = [16, 32], the result tensor has a shape of
...x16x32. If inner_dims_pos = [0, 1], the 0th source dimension is tiled
by 16 and the 1st source dimension is tiled by 32. Other source dimensions
(if any) are not tiled. If inner_dims_pos = [1, 0], the 1st dimension is
tiled by 16 and the 0th dimension is tiled by 32.
Example:
// NC to NCnc
%0 = linalg.pack %source inner_dims_pos = [0, 1] inner_tiles = [8, 32]
into %dest : tensor<128x256xf32> -> tensor<16x8 x 8x32 xf32>
// \ / \ /
// Outer Dims: 16x8 Inner Dims: 8x32
// CHW to CHWhw
%0 = linalg.pack %source inner_dims_pos = [2, 1] inner_tiles = [4, 2]
into %dest : tensor<3x20x24xf32> -> tensor<3x10x6 x 4x2 xf32>
// \ / \ /
// Outer Dims: 3x10x6 Inner Dims: 4x2
// HCW to HCWhw
%0 = linalg.pack %source inner_dims_pos = [2, 0] inner_tiles = [4, 2]
into %dest : tensor<18x3x32xf32> -> tensor<9x3x8 x 4x2 xf32>
// \ / \ /
// Outer Dims: 9x3x8 Inner Dims: 4x2
outer_dims_perm (optional) specifies a permutation for the outer
dimensions. If specified, it must have n elements.
Example:
// CK to KCck
%0 = linalg.pack %source outer_dims_perm = [1, 0] inner_dims_pos = [0, 1]
inner_tiles = [8, 32] into %dest
: tensor<128x256xf32> -> tensor<8x16 x 8x32 xf32>
// \ /
// compare with "NC to NCnc": outer dims are transposed
padding_value specifies a padding value at the boundary on non-perfectly
divisible dimensions. Padding is optional:
- If absent, it is assumed that for all inner tiles,
shape(source)[inner_dims_pos[i]] % inner_tiles[i] == 0, i.e. all inner tiles divide perfectly the corresponding outer dimension in the result tensor. It is UB if the tile does not perfectly divide the dimension. - If present, it will pad along high dimensions (high-padding) to make the tile complete. Note that it is not allowed to have artificial padding that is not strictly required by linalg.pack (i.e., padding past what is needed to complete the last tile along each packed dimension). It is UB if extra padding is requested. It is not possible to verify the requirements statically with dynamic shapes, so they are treated as UB.
Example:
%0 = linalg.pack %arg0 padding_value(%pad : f32) outer_dims_perm = [2, 1, 0]
inner_dims_pos = [1] inner_tiles = [2] into %arg1
: tensor<200x127x256xf32> -> tensor<256x64x200x2xf32>
// \
// padded and tiled dim
//
// Source dimension 1 is tiled. 64 does not divide 127 evenly, so 1 padded
// element is added at the end.
//
// Note: Only tiled dimensions can be padded.
Invalid example that has artificial padding:
%0 = linalg.pack %src padding_value(%cst : f32) inner_dims_pos = [0]
inner_tiles = [8] into %dest
: tensor<9xf32> -> tensor<3x8xf32>
// \
// expect tensor<2x8xf32> because CeilDiv(9, 8) = 2
Traits: AttrSizedOperandSegments
Interfaces: ConditionallySpeculatable, DestinationStyleOpInterface, LinalgRelayoutOpInterface, MemoryEffectOpInterface, OpAsmOpInterface, ReifyRankedShapedTypeOpInterface
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
outer_dims_perm | ::mlir::DenseI64ArrayAttr | i64 dense array attribute |
inner_dims_pos | ::mlir::DenseI64ArrayAttr | i64 dense array attribute |
static_inner_tiles | ::mlir::DenseI64ArrayAttr | i64 dense array attribute |
Operands:
| Operand | Description |
|---|---|
source | Tensor or MemRef of any non-token type values |
dest | Tensor or MemRef of any non-token type values |
padding_value | any non-token type |
inner_tiles | variadic of index |
Results:
| Result | Description |
|---|---|
result | ranked tensor of any non-token type values |
linalg.pooling_nchw_max (linalg::PoolingNchwMaxOp)
Performs max pooling.
Numeric casting is performed on the input operand, promoting it to the same data type as the accumulator/output.
Traits: AttrSizedOperandSegments, RecursiveMemoryEffects, SingleBlockImplicitTerminator<YieldOp>, SingleBlock
Interfaces: ConditionallySpeculatable, DestinationStyleOpInterface, IndexingMapOpInterface, LinalgConvolutionOpInterface, LinalgStructuredInterface, MemoryEffectOpInterface, ReifyRankedShapedTypeOpInterface
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
strides | ::mlir::DenseIntElementsAttr | 64-bit signless int elements attribute of shape [2] |
dilations | ::mlir::DenseIntElementsAttr | 64-bit signless int elements attribute of shape [2] |
Operands:
| Operand | Description |
|---|---|
inputs | variadic of any non-token type |
outputs | variadic of shaped of any non-token type values |
Results:
| Result | Description |
|---|---|
result_tensors | variadic of ranked tensor of any non-token type values |
linalg.pooling_nchw_sum (linalg::PoolingNchwSumOp)
Performs sum pooling.
Layout:
- Input: NCHW.
- Kernel: HW.
Numeric casting is performed on the input operand, promoting it to the same data type as the accumulator/output.
Traits: AttrSizedOperandSegments, RecursiveMemoryEffects, SingleBlockImplicitTerminator<YieldOp>, SingleBlock
Interfaces: ConditionallySpeculatable, DestinationStyleOpInterface, IndexingMapOpInterface, LinalgConvolutionOpInterface, LinalgStructuredInterface, MemoryEffectOpInterface, ReifyRankedShapedTypeOpInterface
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
strides | ::mlir::DenseIntElementsAttr | 64-bit signless int elements attribute of shape [2] |
dilations | ::mlir::DenseIntElementsAttr | 64-bit signless int elements attribute of shape [2] |
Operands:
| Operand | Description |
|---|---|
inputs | variadic of any non-token type |
outputs | variadic of shaped of any non-token type values |
Results:
| Result | Description |
|---|---|
result_tensors | variadic of ranked tensor of any non-token type values |
linalg.pooling_ncw_max (linalg::PoolingNcwMaxOp)
Performs max pooling.
Numeric casting is performed on the input operand, promoting it to the same data type as the accumulator/output.
Traits: AttrSizedOperandSegments, RecursiveMemoryEffects, SingleBlockImplicitTerminator<YieldOp>, SingleBlock
Interfaces: ConditionallySpeculatable, DestinationStyleOpInterface, IndexingMapOpInterface, LinalgConvolutionOpInterface, LinalgStructuredInterface, MemoryEffectOpInterface, ReifyRankedShapedTypeOpInterface
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
strides | ::mlir::DenseIntElementsAttr | 64-bit signless int elements attribute of shape [1] |
dilations | ::mlir::DenseIntElementsAttr | 64-bit signless int elements attribute of shape [1] |
Operands:
| Operand | Description |
|---|---|
inputs | variadic of any non-token type |
outputs | variadic of shaped of any non-token type values |
Results:
| Result | Description |
|---|---|
result_tensors | variadic of ranked tensor of any non-token type values |
linalg.pooling_ncw_sum (linalg::PoolingNcwSumOp)
Performs sum pooling.
Layout:
- Input: NCW.
- Kernel: W.
Numeric casting is performed on the input operand, promoting it to the same data type as the accumulator/output.
Traits: AttrSizedOperandSegments, RecursiveMemoryEffects, SingleBlockImplicitTerminator<YieldOp>, SingleBlock
Interfaces: ConditionallySpeculatable, DestinationStyleOpInterface, IndexingMapOpInterface, LinalgConvolutionOpInterface, LinalgStructuredInterface, MemoryEffectOpInterface, ReifyRankedShapedTypeOpInterface
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
strides | ::mlir::DenseIntElementsAttr | 64-bit signless int elements attribute of shape [1] |
dilations | ::mlir::DenseIntElementsAttr | 64-bit signless int elements attribute of shape [1] |
Operands:
| Operand | Description |
|---|---|
inputs | variadic of any non-token type |
outputs | variadic of shaped of any non-token type values |
Results:
| Result | Description |
|---|---|
result_tensors | variadic of ranked tensor of any non-token type values |
linalg.pooling_ndhwc_max (linalg::PoolingNdhwcMaxOp)
Performs 3D max pooling.
Numeric casting is performed on the input operand, promoting it to the same data type as the accumulator/output.
Traits: AttrSizedOperandSegments, RecursiveMemoryEffects, SingleBlockImplicitTerminator<YieldOp>, SingleBlock
Interfaces: ConditionallySpeculatable, DestinationStyleOpInterface, IndexingMapOpInterface, LinalgConvolutionOpInterface, LinalgStructuredInterface, MemoryEffectOpInterface, ReifyRankedShapedTypeOpInterface
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
strides | ::mlir::DenseIntElementsAttr | 64-bit signless int elements attribute of shape [3] |
dilations | ::mlir::DenseIntElementsAttr | 64-bit signless int elements attribute of shape [3] |
Operands:
| Operand | Description |
|---|---|
inputs | variadic of any non-token type |
outputs | variadic of shaped of any non-token type values |
Results:
| Result | Description |
|---|---|
result_tensors | variadic of ranked tensor of any non-token type values |
linalg.pooling_ndhwc_min (linalg::PoolingNdhwcMinOp)
Performs 3D min pooling.
Numeric casting is performed on the input operand, promoting it to the same data type as the accumulator/output.
Traits: AttrSizedOperandSegments, RecursiveMemoryEffects, SingleBlockImplicitTerminator<YieldOp>, SingleBlock
Interfaces: ConditionallySpeculatable, DestinationStyleOpInterface, IndexingMapOpInterface, LinalgConvolutionOpInterface, LinalgStructuredInterface, MemoryEffectOpInterface, ReifyRankedShapedTypeOpInterface
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
strides | ::mlir::DenseIntElementsAttr | 64-bit signless int elements attribute of shape [3] |
dilations | ::mlir::DenseIntElementsAttr | 64-bit signless int elements attribute of shape [3] |
Operands:
| Operand | Description |
|---|---|
inputs | variadic of any non-token type |
outputs | variadic of shaped of any non-token type values |
Results:
| Result | Description |
|---|---|
result_tensors | variadic of ranked tensor of any non-token type values |
linalg.pooling_ndhwc_sum (linalg::PoolingNdhwcSumOp)
Performs 3D sum pooling.
Numeric casting is performed on the input operand, promoting it to the same data type as the accumulator/output.
Traits: AttrSizedOperandSegments, RecursiveMemoryEffects, SingleBlockImplicitTerminator<YieldOp>, SingleBlock
Interfaces: ConditionallySpeculatable, DestinationStyleOpInterface, IndexingMapOpInterface, LinalgConvolutionOpInterface, LinalgStructuredInterface, MemoryEffectOpInterface, ReifyRankedShapedTypeOpInterface
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
strides | ::mlir::DenseIntElementsAttr | 64-bit signless int elements attribute of shape [3] |
dilations | ::mlir::DenseIntElementsAttr | 64-bit signless int elements attribute of shape [3] |
Operands:
| Operand | Description |
|---|---|
inputs | variadic of any non-token type |
outputs | variadic of shaped of any non-token type values |
Results:
| Result | Description |
|---|---|
result_tensors | variadic of ranked tensor of any non-token type values |
linalg.pooling_nhwc_max (linalg::PoolingNhwcMaxOp)
Performs max pooling.
Numeric casting is performed on the input operand, promoting it to the same data type as the accumulator/output.
Traits: AttrSizedOperandSegments, RecursiveMemoryEffects, SingleBlockImplicitTerminator<YieldOp>, SingleBlock
Interfaces: ConditionallySpeculatable, DestinationStyleOpInterface, IndexingMapOpInterface, LinalgConvolutionOpInterface, LinalgStructuredInterface, MemoryEffectOpInterface, ReifyRankedShapedTypeOpInterface
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
strides | ::mlir::DenseIntElementsAttr | 64-bit signless int elements attribute of shape [2] |
dilations | ::mlir::DenseIntElementsAttr | 64-bit signless int elements attribute of shape [2] |
Operands:
| Operand | Description |
|---|---|
inputs | variadic of any non-token type |
outputs | variadic of shaped of any non-token type values |
Results:
| Result | Description |
|---|---|
result_tensors | variadic of ranked tensor of any non-token type values |
linalg.pooling_nhwc_max_unsigned (linalg::PoolingNhwcMaxUnsignedOp)
Performs unsigned max pooling.
Numeric casting is performed on the input operand, promoting it to the same data type as the accumulator/output.
Traits: AttrSizedOperandSegments, RecursiveMemoryEffects, SingleBlockImplicitTerminator<YieldOp>, SingleBlock
Interfaces: ConditionallySpeculatable, DestinationStyleOpInterface, IndexingMapOpInterface, LinalgConvolutionOpInterface, LinalgStructuredInterface, MemoryEffectOpInterface, ReifyRankedShapedTypeOpInterface
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
strides | ::mlir::DenseIntElementsAttr | 64-bit signless int elements attribute of shape [2] |
dilations | ::mlir::DenseIntElementsAttr | 64-bit signless int elements attribute of shape [2] |
Operands:
| Operand | Description |
|---|---|
inputs | variadic of any non-token type |
outputs | variadic of shaped of any non-token type values |
Results:
| Result | Description |
|---|---|
result_tensors | variadic of ranked tensor of any non-token type values |
linalg.pooling_nhwc_min (linalg::PoolingNhwcMinOp)
Performs min pooling.
Numeric casting is performed on the input operand, promoting it to the same data type as the accumulator/output.
Traits: AttrSizedOperandSegments, RecursiveMemoryEffects, SingleBlockImplicitTerminator<YieldOp>, SingleBlock
Interfaces: ConditionallySpeculatable, DestinationStyleOpInterface, IndexingMapOpInterface, LinalgConvolutionOpInterface, LinalgStructuredInterface, MemoryEffectOpInterface, ReifyRankedShapedTypeOpInterface
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
strides | ::mlir::DenseIntElementsAttr | 64-bit signless int elements attribute of shape [2] |
dilations | ::mlir::DenseIntElementsAttr | 64-bit signless int elements attribute of shape [2] |
Operands:
| Operand | Description |
|---|---|
inputs | variadic of any non-token type |
outputs | variadic of shaped of any non-token type values |
Results:
| Result | Description |
|---|---|
result_tensors | variadic of ranked tensor of any non-token type values |
linalg.pooling_nhwc_min_unsigned (linalg::PoolingNhwcMinUnsignedOp)
Performs unsigned min pooling.
Numeric casting is performed on the input operand, promoting it to the same data type as the accumulator/output.
Traits: AttrSizedOperandSegments, RecursiveMemoryEffects, SingleBlockImplicitTerminator<YieldOp>, SingleBlock
Interfaces: ConditionallySpeculatable, DestinationStyleOpInterface, IndexingMapOpInterface, LinalgConvolutionOpInterface, LinalgStructuredInterface, MemoryEffectOpInterface, ReifyRankedShapedTypeOpInterface
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
strides | ::mlir::DenseIntElementsAttr | 64-bit signless int elements attribute of shape [2] |
dilations | ::mlir::DenseIntElementsAttr | 64-bit signless int elements attribute of shape [2] |
Operands:
| Operand | Description |
|---|---|
inputs | variadic of any non-token type |
outputs | variadic of shaped of any non-token type values |
Results:
| Result | Description |
|---|---|
result_tensors | variadic of ranked tensor of any non-token type values |
linalg.pooling_nhwc_sum (linalg::PoolingNhwcSumOp)
Performs sum pooling.
Layout:
- Input: NHWC.
- Kernel: HW.
Numeric casting is performed on the input operand, promoting it to the same data type as the accumulator/output.
Traits: AttrSizedOperandSegments, RecursiveMemoryEffects, SingleBlockImplicitTerminator<YieldOp>, SingleBlock
Interfaces: ConditionallySpeculatable, DestinationStyleOpInterface, IndexingMapOpInterface, LinalgConvolutionOpInterface, LinalgStructuredInterface, MemoryEffectOpInterface, ReifyRankedShapedTypeOpInterface
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
strides | ::mlir::DenseIntElementsAttr | 64-bit signless int elements attribute of shape [2] |
dilations | ::mlir::DenseIntElementsAttr | 64-bit signless int elements attribute of shape [2] |
Operands:
| Operand | Description |
|---|---|
inputs | variadic of any non-token type |
outputs | variadic of shaped of any non-token type values |
Results:
| Result | Description |
|---|---|
result_tensors | variadic of ranked tensor of any non-token type values |
linalg.pooling_nwc_max (linalg::PoolingNwcMaxOp)
Performs max pooling.
Numeric casting is performed on the input operand, promoting it to the same data type as the accumulator/output.
Traits: AttrSizedOperandSegments, RecursiveMemoryEffects, SingleBlockImplicitTerminator<YieldOp>, SingleBlock
Interfaces: ConditionallySpeculatable, DestinationStyleOpInterface, IndexingMapOpInterface, LinalgConvolutionOpInterface, LinalgStructuredInterface, MemoryEffectOpInterface, ReifyRankedShapedTypeOpInterface
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
strides | ::mlir::DenseIntElementsAttr | 64-bit signless int elements attribute of shape [1] |
dilations | ::mlir::DenseIntElementsAttr | 64-bit signless int elements attribute of shape [1] |
Operands:
| Operand | Description |
|---|---|
inputs | variadic of any non-token type |
outputs | variadic of shaped of any non-token type values |
Results:
| Result | Description |
|---|---|
result_tensors | variadic of ranked tensor of any non-token type values |
linalg.pooling_nwc_max_unsigned (linalg::PoolingNwcMaxUnsignedOp)
Performs unsigned max pooling.
Numeric casting is performed on the input operand, promoting it to the same data type as the accumulator/output.
Traits: AttrSizedOperandSegments, RecursiveMemoryEffects, SingleBlockImplicitTerminator<YieldOp>, SingleBlock
Interfaces: ConditionallySpeculatable, DestinationStyleOpInterface, IndexingMapOpInterface, LinalgConvolutionOpInterface, LinalgStructuredInterface, MemoryEffectOpInterface, ReifyRankedShapedTypeOpInterface
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
strides | ::mlir::DenseIntElementsAttr | 64-bit signless int elements attribute of shape [1] |
dilations | ::mlir::DenseIntElementsAttr | 64-bit signless int elements attribute of shape [1] |
Operands:
| Operand | Description |
|---|---|
inputs | variadic of any non-token type |
outputs | variadic of shaped of any non-token type values |
Results:
| Result | Description |
|---|---|
result_tensors | variadic of ranked tensor of any non-token type values |
linalg.pooling_nwc_min (linalg::PoolingNwcMinOp)
Performs min pooling.
Numeric casting is performed on the input operand, promoting it to the same data type as the accumulator/output.
Traits: AttrSizedOperandSegments, RecursiveMemoryEffects, SingleBlockImplicitTerminator<YieldOp>, SingleBlock
Interfaces: ConditionallySpeculatable, DestinationStyleOpInterface, IndexingMapOpInterface, LinalgConvolutionOpInterface, LinalgStructuredInterface, MemoryEffectOpInterface, ReifyRankedShapedTypeOpInterface
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
strides | ::mlir::DenseIntElementsAttr | 64-bit signless int elements attribute of shape [1] |
dilations | ::mlir::DenseIntElementsAttr | 64-bit signless int elements attribute of shape [1] |
Operands:
| Operand | Description |
|---|---|
inputs | variadic of any non-token type |
outputs | variadic of shaped of any non-token type values |
Results:
| Result | Description |
|---|---|
result_tensors | variadic of ranked tensor of any non-token type values |
linalg.pooling_nwc_min_unsigned (linalg::PoolingNwcMinUnsignedOp)
Performs unsigned min pooling.
Numeric casting is performed on the input operand, promoting it to the same data type as the accumulator/output.
Traits: AttrSizedOperandSegments, RecursiveMemoryEffects, SingleBlockImplicitTerminator<YieldOp>, SingleBlock
Interfaces: ConditionallySpeculatable, DestinationStyleOpInterface, IndexingMapOpInterface, LinalgConvolutionOpInterface, LinalgStructuredInterface, MemoryEffectOpInterface, ReifyRankedShapedTypeOpInterface
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
strides | ::mlir::DenseIntElementsAttr | 64-bit signless int elements attribute of shape [1] |
dilations | ::mlir::DenseIntElementsAttr | 64-bit signless int elements attribute of shape [1] |
Operands:
| Operand | Description |
|---|---|
inputs | variadic of any non-token type |
outputs | variadic of shaped of any non-token type values |
Results:
| Result | Description |
|---|---|
result_tensors | variadic of ranked tensor of any non-token type values |
linalg.pooling_nwc_sum (linalg::PoolingNwcSumOp)
Performs sum pooling.
Layout:
- Input: NWC.
- Kernel: W.
Numeric casting is performed on the input operand, promoting it to the same data type as the accumulator/output.
Traits: AttrSizedOperandSegments, RecursiveMemoryEffects, SingleBlockImplicitTerminator<YieldOp>, SingleBlock
Interfaces: ConditionallySpeculatable, DestinationStyleOpInterface, IndexingMapOpInterface, LinalgConvolutionOpInterface, LinalgStructuredInterface, MemoryEffectOpInterface, ReifyRankedShapedTypeOpInterface
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
strides | ::mlir::DenseIntElementsAttr | 64-bit signless int elements attribute of shape [1] |
dilations | ::mlir::DenseIntElementsAttr | 64-bit signless int elements attribute of shape [1] |
Operands:
| Operand | Description |
|---|---|
inputs | variadic of any non-token type |
outputs | variadic of shaped of any non-token type values |
Results:
| Result | Description |
|---|---|
result_tensors | variadic of ranked tensor of any non-token type values |
linalg.powf (linalg::PowFOp)
Takes the powf(lhs, rhs) between two inputs, elementwise. For powf(arg, 2) use linalg.square.
Only applies to floating point values.
The shapes and element types must be identical. The appropriate casts, broadcasts and reductions should be done previously to calling this op.
This means reduction/broadcast/element cast semantics is explicit. Further
passes can take that into account when lowering this code. For example,
a linalg.broadcast + linalg.powf sequence can be lowered to a
linalg.generic with different affine maps for the two operands.
Traits: AttrSizedOperandSegments, RecursiveMemoryEffects, SingleBlockImplicitTerminator<YieldOp>, SingleBlock
Interfaces: ConditionallySpeculatable, DestinationStyleOpInterface, IndexingMapOpInterface, LinalgStructuredInterface, MemoryEffectOpInterface, ReifyRankedShapedTypeOpInterface
Operands:
| Operand | Description |
|---|---|
inputs | variadic of any non-token type |
outputs | variadic of shaped of any non-token type values |
Results:
| Result | Description |
|---|---|
result_tensors | variadic of ranked tensor of any non-token type values |
linalg.quantized_batch_matmul (linalg::QuantizedBatchMatmulOp)
Performs a batched matrix multiplication of two 3D inputs.
Numeric casting is performed on the operands to the inner multiply, promoting them to the same data type as the accumulator/output. The quantized variant includes zero-point adjustments for the left and right operands of the matmul.
Traits: AttrSizedOperandSegments, RecursiveMemoryEffects, SingleBlockImplicitTerminator<YieldOp>, SingleBlock
Interfaces: ConditionallySpeculatable, DestinationStyleOpInterface, IndexingMapOpInterface, LinalgStructuredInterface, MemoryEffectOpInterface, ReifyRankedShapedTypeOpInterface
Operands:
| Operand | Description |
|---|---|
inputs | variadic of any non-token type |
outputs | variadic of shaped of any non-token type values |
Results:
| Result | Description |
|---|---|
result_tensors | variadic of ranked tensor of any non-token type values |
linalg.quantized_matmul (linalg::QuantizedMatmulOp)
Performs a matrix multiplication of two 2D inputs.
Numeric casting is performed on the operands to the inner multiply, promoting them to the same data type as the accumulator/output. The quantized variant includes zero-point adjustments for the left and right operands of the matmul.
Traits: AttrSizedOperandSegments, RecursiveMemoryEffects, SingleBlockImplicitTerminator<YieldOp>, SingleBlock
Interfaces: ConditionallySpeculatable, DestinationStyleOpInterface, IndexingMapOpInterface, LinalgStructuredInterface, MemoryEffectOpInterface, ReifyRankedShapedTypeOpInterface
Operands:
| Operand | Description |
|---|---|
inputs | variadic of any non-token type |
outputs | variadic of shaped of any non-token type values |
Results:
| Result | Description |
|---|---|
result_tensors | variadic of ranked tensor of any non-token type values |
linalg.reciprocal (linalg::ReciprocalOp)
Applies reciprocal(x) elementwise.
No numeric casting is performed on the input operand.
Traits: AttrSizedOperandSegments, RecursiveMemoryEffects, SingleBlockImplicitTerminator<YieldOp>, SingleBlock
Interfaces: ConditionallySpeculatable, DestinationStyleOpInterface, IndexingMapOpInterface, LinalgStructuredInterface, MemoryEffectOpInterface, ReifyRankedShapedTypeOpInterface
Operands:
| Operand | Description |
|---|---|
inputs | variadic of any non-token type |
outputs | variadic of shaped of any non-token type values |
Results:
| Result | Description |
|---|---|
result_tensors | variadic of ranked tensor of any non-token type values |
linalg.reduce (linalg::ReduceOp)
Reduce operator
Executes combiner on the dimensions of inputs and returns the
reduced result. The dimensions attribute needs to list the reduction
dimensions in increasing order.
Example:
%reduce = linalg.reduce
ins(%input:tensor<16x32x64xf32>)
outs(%init:tensor<16x64xf32>)
dimensions = [1]
(%in: f32, %out: f32) {
%0 = arith.addf %out, %in: f32
linalg.yield %0: f32
}
Shortened print form is available for simple reduces where the body contains exactly two operations (the payload operation and a yield), the payload operation has the same number of operands as block arguments, the first block argument (init) is the last operand of the payload operation with remaining operands matching remaining block arguments in order, and the yield operand is the result of the payload operation.
The example above will be printed using the shortened form as:
%reduce = linalg.reduce { arith.addf }
ins(%input:tensor<16x32x64xf32>)
outs(%init:tensor<16x64xf32>)
dimensions = [1]
Traits: RecursiveMemoryEffects, SameVariadicOperandSize, SingleBlockImplicitTerminator<YieldOp>, SingleBlock
Interfaces: ConditionallySpeculatable, DestinationStyleOpInterface, IndexingMapOpInterface, LinalgStructuredInterface, MemoryEffectOpInterface, OpAsmOpInterface, ReifyRankedShapedTypeOpInterface
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
dimensions | ::mlir::DenseI64ArrayAttr | i64 dense array attribute should be in increasing order |
Operands:
| Operand | Description |
|---|---|
inputs | variadic of memref of any non-token type values or ranked tensor of any non-token type values |
inits | variadic of memref of any non-token type values or ranked tensor of any non-token type values |
Results:
| Result | Description |
|---|---|
| «unnamed» | variadic of tensor of any non-token type values |
linalg.round (linalg::RoundOp)
Applies round(x) elementwise.
No numeric casting is performed on the input operand.
Traits: AttrSizedOperandSegments, RecursiveMemoryEffects, SingleBlockImplicitTerminator<YieldOp>, SingleBlock
Interfaces: ConditionallySpeculatable, DestinationStyleOpInterface, IndexingMapOpInterface, LinalgStructuredInterface, MemoryEffectOpInterface, ReifyRankedShapedTypeOpInterface
Operands:
| Operand | Description |
|---|---|
inputs | variadic of any non-token type |
outputs | variadic of shaped of any non-token type values |
Results:
| Result | Description |
|---|---|
result_tensors | variadic of ranked tensor of any non-token type values |
linalg.rsqrt (linalg::RsqrtOp)
Applies rsqrt(x) elementwise.
No numeric casting is performed on the input operand.
Traits: AttrSizedOperandSegments, RecursiveMemoryEffects, SingleBlockImplicitTerminator<YieldOp>, SingleBlock
Interfaces: ConditionallySpeculatable, DestinationStyleOpInterface, IndexingMapOpInterface, LinalgStructuredInterface, MemoryEffectOpInterface, ReifyRankedShapedTypeOpInterface
Operands:
| Operand | Description |
|---|---|
inputs | variadic of any non-token type |
outputs | variadic of shaped of any non-token type values |
Results:
| Result | Description |
|---|---|
result_tensors | variadic of ranked tensor of any non-token type values |
linalg.select (linalg::SelectOp)
Chooses one value based on a binary condition supplied as its first operand.
The shapes and element types must be identical. The appropriate casts, broadcasts and reductions should be done previously to calling this op.
This means reduction/broadcast/element cast semantics is explicit. Further
passes can take that into account when lowering this code. For example,
a linalg.broadcast + linalg.select sequence can be lowered to a
linalg.generic with different affine maps for the two operands.
Traits: AttrSizedOperandSegments, RecursiveMemoryEffects, SingleBlockImplicitTerminator<YieldOp>, SingleBlock
Interfaces: ConditionallySpeculatable, DestinationStyleOpInterface, IndexingMapOpInterface, LinalgStructuredInterface, MemoryEffectOpInterface, ReifyRankedShapedTypeOpInterface
Operands:
| Operand | Description |
|---|---|
inputs | variadic of any non-token type |
outputs | variadic of shaped of any non-token type values |
Results:
| Result | Description |
|---|---|
result_tensors | variadic of ranked tensor of any non-token type values |
linalg.softmax (linalg::SoftmaxOp)
Softmax operator
Syntax:
operation ::= `linalg.softmax` attr-dict
`dimension` `(` $dimension `)`
`ins` `(` $input `:` type($input) `)`
`outs` `(` $output `:` type($output) `)`
(`->` type($result)^)?
linalg.softmax computes a numerically stable version of softmax.
For a given input tensor and a specified dimension d, compute:
- the max
malong that dimensiond - f(x) = exp(x - m)
- sum f(x) along dimension d to get l(x).
- compute the final result f(x) / l(x).
This is an aggregate linalg operation that further reduces to a small DAG of structured operations.
Warning: Regarding the tiling capabilities, the implementation doesn’t check that the provided dimensions make sense. This is the responsability of the transformation calling the tiling to ensure that the provided sizes for each dimension make sense with respect to the semantic of softmax.
Interfaces: AggregatedOpInterface, DestinationStyleOpInterface, MemoryEffectOpInterface, ReifyRankedShapedTypeOpInterface, TilingInterface
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
dimension | ::mlir::IntegerAttr | 64-bit signless integer attribute |
Operands:
| Operand | Description |
|---|---|
input | shaped of any non-token type values |
output | shaped of any non-token type values |
Results:
| Result | Description |
|---|---|
result | variadic of ranked tensor of any non-token type values |
linalg.sqrt (linalg::SqrtOp)
Applies sqrt(x) elementwise.
No numeric casting is performed on the input operand.
Traits: AttrSizedOperandSegments, RecursiveMemoryEffects, SingleBlockImplicitTerminator<YieldOp>, SingleBlock
Interfaces: ConditionallySpeculatable, DestinationStyleOpInterface, IndexingMapOpInterface, LinalgStructuredInterface, MemoryEffectOpInterface, ReifyRankedShapedTypeOpInterface
Operands:
| Operand | Description |
|---|---|
inputs | variadic of any non-token type |
outputs | variadic of shaped of any non-token type values |
Results:
| Result | Description |
|---|---|
result_tensors | variadic of ranked tensor of any non-token type values |
linalg.square (linalg::SquareOp)
Applies square(x) elementwise.
No numeric casting is performed on the input operand.
Traits: AttrSizedOperandSegments, RecursiveMemoryEffects, SingleBlockImplicitTerminator<YieldOp>, SingleBlock
Interfaces: ConditionallySpeculatable, DestinationStyleOpInterface, IndexingMapOpInterface, LinalgStructuredInterface, MemoryEffectOpInterface, ReifyRankedShapedTypeOpInterface
Operands:
| Operand | Description |
|---|---|
inputs | variadic of any non-token type |
outputs | variadic of shaped of any non-token type values |
Results:
| Result | Description |
|---|---|
result_tensors | variadic of ranked tensor of any non-token type values |
linalg.sub (linalg::SubOp)
Subtracts two tensors elementwise.
The shapes and element types must be identical. The appropriate casts, broadcasts and reductions should be done previously to calling this op.
This means reduction/broadcast/element cast semantics is explicit. Further
passes can take that into account when lowering this code. For example,
a linalg.broadcast + linalg.sub sequence can be lowered to a
linalg.generic with different affine maps for the two operands.
Traits: AttrSizedOperandSegments, RecursiveMemoryEffects, SingleBlockImplicitTerminator<YieldOp>, SingleBlock
Interfaces: ConditionallySpeculatable, DestinationStyleOpInterface, IndexingMapOpInterface, LinalgStructuredInterface, MemoryEffectOpInterface, ReifyRankedShapedTypeOpInterface
Operands:
| Operand | Description |
|---|---|
inputs | variadic of any non-token type |
outputs | variadic of shaped of any non-token type values |
Results:
| Result | Description |
|---|---|
result_tensors | variadic of ranked tensor of any non-token type values |
linalg.tanh (linalg::TanhOp)
Applies tanh(x) elementwise.
No numeric casting is performed on the input operand.
Traits: AttrSizedOperandSegments, RecursiveMemoryEffects, SingleBlockImplicitTerminator<YieldOp>, SingleBlock
Interfaces: ConditionallySpeculatable, DestinationStyleOpInterface, IndexingMapOpInterface, LinalgStructuredInterface, MemoryEffectOpInterface, ReifyRankedShapedTypeOpInterface
Operands:
| Operand | Description |
|---|---|
inputs | variadic of any non-token type |
outputs | variadic of shaped of any non-token type values |
Results:
| Result | Description |
|---|---|
result_tensors | variadic of ranked tensor of any non-token type values |
linalg.transpose (linalg::TransposeOp)
Transpose operator
Permutes the dimensions of input according to the given permutation.
dim(result, i) = dim(input, permutation[i])
This op actually moves data, unlike memref.transpose which is a metadata
operation only that produces a transposed “view”.
Example:
%transpose = linalg.transpose
ins(%input:tensor<16x64xf32>)
outs(%init:tensor<64x16xf32>)
permutation = [1, 0]
Traits: RecursiveMemoryEffects, SingleBlockImplicitTerminator<YieldOp>, SingleBlock
Interfaces: ConditionallySpeculatable, DestinationStyleOpInterface, IndexingMapOpInterface, LinalgStructuredInterface, MemoryEffectOpInterface, OpAsmOpInterface, ReifyRankedShapedTypeOpInterface
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
permutation | ::mlir::DenseI64ArrayAttr | i64 dense array attribute |
Operands:
| Operand | Description |
|---|---|
input | memref of any non-token type values or ranked tensor of any non-token type values |
init | memref of any non-token type values or ranked tensor of any non-token type values |
Results:
| Result | Description |
|---|---|
result | variadic of tensor of any non-token type values |
linalg.unpack (linalg::UnPackOp)
Linalg.unpack operation
The “unpack” operation converts a source tensor of rank n with a tiled and
packed layout to a result tensor of rank n - k.
inner_tiles (mandatory) specifies k tile sizes. These tile sizes
correspond to the least significant (“inner”) source tensor dimension sizes.
The behavior of this op is undefined if:
inner_tilesdo not exactly match with the corresponding source tensor dimension sizes.- Or,
inner_tiles[i]does not divide the size of dimensioninner_dims_pos[i](assuming thatouter_dims_permis not specified) evenly.
inner_dims_pos (mandatory) specifies k result tensor (i.e. unpacked
tensor) dimensions that were tiled with the inner_tiles to create the
packed source tensor. The source tensor (i.e. packed tensor) dimensions can
be unpacked given inner_dims_pos as follows.
- For
0 <= i < kthe following relationship holds:shape(result)[inner_dims_pos[i]] <= shape(source)[n-k+i] * shape(source)[inner_dims_pos[i]]. - For
0 <= j < n-kandjnot ininner_dims_posthe following relationship holds:shape(result)[j] = shape(source)[j].
outer_dims_perm (optional) specifies a permutation for the outer
dimensions. If specified, it must have n - k elements. If specified, this
permutation is applied before combining any dimensions.
Note, the unpack operation may drop any padding introduced by the pack
operation and hence the following holds
NumElementsOf(source) >= NumElementsOf(result).
Examples:
// NCnc to NC:
%0 = linalg.unpack %source inner_dims_pos = [0, 1] inner_tiles = [8, 32]
into %dest : tensor<16x8 x 8x32 xf32> -> tensor<128x256xf32>
// \ / \ /
// Outer Dims: 16x8 Inner Dims: 8x32
// CK to KCck:
%0 = linalg.unpack %source outer_dims_perm = [1, 0] inner_dims_pos = [0, 1]
inner_tiles = [8, 32]
into %dest : tensor<8x16 x 8x32 xf32> -> tensor<128x256xf32>
// \ / \ /
// Outer Dims: 8x16 Inner Dims: 8x32
// CHW to CHWhw:
%0 = linalg.unpack %source inner_dims_pos = [2, 1] inner_tiles = [4, 2]
into %dest : tensor<3x10x6 x 4x2 xf32> -> tensor<3x20x24xf32>
// \ / \ /
// Outer Dims: 3x10x6 Inner Dims: 4x2
// HCW to HCWhw
%0 = linalg.unpack %source inner_dims_pos = [2, 0] inner_tiles = [4, 2]
into %dest : tensor<9x3x8 x 4x2 xf32> -> tensor<18x3x32xf32>
// \ / \ /
// Outer Dims: 9x3x8 Inner Dims: 4x2
Interfaces: ConditionallySpeculatable, DestinationStyleOpInterface, LinalgRelayoutOpInterface, MemoryEffectOpInterface, OpAsmOpInterface, ReifyRankedShapedTypeOpInterface
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
outer_dims_perm | ::mlir::DenseI64ArrayAttr | i64 dense array attribute |
inner_dims_pos | ::mlir::DenseI64ArrayAttr | i64 dense array attribute |
static_inner_tiles | ::mlir::DenseI64ArrayAttr | i64 dense array attribute |
Operands:
| Operand | Description |
|---|---|
source | Tensor or MemRef of any non-token type values |
dest | Tensor or MemRef of any non-token type values |
inner_tiles | variadic of index |
Results:
| Result | Description |
|---|---|
result | ranked tensor of any non-token type values |
linalg.vecmat (linalg::VecmatOp)
Performs a vector-matrix multiplication.
Numeric casting is performed on the operands to the inner multiply, promoting them to the same data type as the accumulator/output.
Traits: AttrSizedOperandSegments, RecursiveMemoryEffects, SingleBlockImplicitTerminator<YieldOp>, SingleBlock
Interfaces: ConditionallySpeculatable, DestinationStyleOpInterface, IndexingMapOpInterface, LinalgContractionOpInterface, LinalgStructuredInterface, MemoryEffectOpInterface, ReifyRankedShapedTypeOpInterface
Operands:
| Operand | Description |
|---|---|
inputs | variadic of any non-token type |
outputs | variadic of shaped of any non-token type values |
Results:
| Result | Description |
|---|---|
result_tensors | variadic of ranked tensor of any non-token type values |
linalg.winograd_filter_transform (linalg::WinogradFilterTransformOp)
Winograd filter transform operator
Syntax:
operation ::= `linalg.winograd_filter_transform` attr-dict
`fmr` `(` $fmr `)`
`ins` `(` $filter `:` type($filter) `)`
`outs` `(` $output `:` type($output) `)`
`->` type($result)
Winograd Conv2D algorithm will convert linalg Conv2D operator into batched matrix multiply. Before the matrix multiply, it will convert filter and input into a format suitable for batched matrix multiply. After the matrix multiply, it will convert output to the final result tensor.
The algorithm F(m x m, r x r) is
Y = A^T x [(G x g x G^T) @ (B^T x d x B)] x A
The size of output Y is m x m. The size of filter g is r x r. The size of input d is (m + r - 1) x (m + r - 1). A^T, A, G^T, G, B^T, and B are transformation matrices.
This operator is defined to represent the high level concept of filter transformation (G x g x G^T) in the Winograd Conv2D algorithm.
Interfaces: DestinationStyleOpInterface, TilingInterface
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
fmr | mlir::linalg::WinogradConv2DFmrAttr | allowed 32-bit signless integer cases: 0, 1, 2 |
Operands:
| Operand | Description |
|---|---|
filter | 4D tensor of any non-token type values |
output | 4D tensor of any non-token type values |
Results:
| Result | Description |
|---|---|
result | 4D tensor of any non-token type values |
linalg.winograd_input_transform (linalg::WinogradInputTransformOp)
Winograd input transform operator
Syntax:
operation ::= `linalg.winograd_input_transform` attr-dict
`fmr` `(` $fmr `)`
`ins` `(` $input `:` type($input) `)`
`outs` `(` $output `:` type($output) `)`
`->` type($result)
Winograd Conv2D algorithm will convert linalg Conv2D operator into batched matrix multiply. Before the matrix multiply, it will convert filter and input into a format suitable for batched matrix multiply. After the matrix multiply, it will convert output to the final result tensor.
The algorithm F(m x m, r x r) is
Y = A^T x [(G x g x G^T) @ (B^T x d x B)] x A
The size of output Y is m x m. The size of filter g is r x r. The size of input d is (m + r - 1) x (m + r - 1). A^T, A, G^T, G, B^T, and B are transformation matrices.
This operator is defined to represent the high level concept of input transformation (B^T x d x B) in the Winograd Conv2D algorithm.
Interfaces: DestinationStyleOpInterface, TilingInterface
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
fmr | mlir::linalg::WinogradConv2DFmrAttr | allowed 32-bit signless integer cases: 0, 1, 2 |
Operands:
| Operand | Description |
|---|---|
input | 4D tensor of any non-token type values |
output | 6D tensor of any non-token type values |
Results:
| Result | Description |
|---|---|
result | 6D tensor of any non-token type values |
linalg.winograd_output_transform (linalg::WinogradOutputTransformOp)
Winograd output transform operator
Syntax:
operation ::= `linalg.winograd_output_transform` attr-dict
`fmr` `(` $fmr `)`
`ins` `(` $value `:` type($value) `)`
`outs` `(` $output `:` type($output) `)`
`->` type($result)
Winograd Conv2D algorithm will convert linalg Conv2D operator into batched matrix multiply. Before the matrix multiply, it will convert filter and input into a format suitable for batched matrix multiply. After the matrix multiply, it will convert output to the final result tensor.
The algorithm F(m x m, r x r) is
Y = A^T x [(G x g x G^T) @ (B^T x d x B)] x A
The size of output Y is m x m. The size of filter g is r x r. The size of input d is (m + r - 1) x (m + r - 1). A^T, A, G^T, G, B^T, and B are transformation matrices.
This operator is defined to represent the high level concept of output transformation (A^T x y x A) in the Winograd Conv2D algorithm.
Interfaces: DestinationStyleOpInterface, TilingInterface
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
fmr | mlir::linalg::WinogradConv2DFmrAttr | allowed 32-bit signless integer cases: 0, 1, 2 |
Operands:
| Operand | Description |
|---|---|
value | 6D tensor of any non-token type values |
output | 4D tensor of any non-token type values |
Results:
| Result | Description |
|---|---|
result | 4D tensor of any non-token type values |
linalg.yield (linalg::YieldOp)
Linalg yield operation
linalg.yield is a special terminator operation for blocks inside regions
in linalg generic ops. It returns values to the immediately enclosing
linalg generic op.
Example:
linalg.yield %f0, %f1 : f32, f32
Traits: AlwaysSpeculatableImplTrait, ReturnLike, Terminator
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), RegionBranchTerminatorOpInterface
Effects: MemoryEffects::Effect{}
Operands:
| Operand | Description |
|---|---|
values | variadic of any non-token type |